09 Jan 2011
Gist adalah fitur yang disediakan oleh Github. Fungsi dasarnya mirip dengan pastebin, yaitu kita bisa paste text di sana, dan disharing dengan orang lain. Keunggulan Gist adalah dia sudah memiliki kemampuan version control dengan Git. Sehingga kita bisa fork, clone, modifikasi, dan push lagi ke repo utama dengan seluruh history tersimpan di sana.
Untuk bisa menggunakan Gist, kita harus memiliki account Github dulu. Setelah itu, kita bisa buat gist di sini.
Cara membuatnya tidak sulit. Cukup entri nama file, keterangan, dan isi text yang mau dishare.

Setelah itu, tekan Create Public Gist. Gist kita akan siap digunakan.
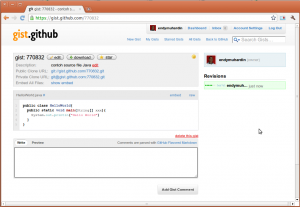
Gist yang sudah dibuat bisa dipasang di blog. Caranya, klik tombol embed.
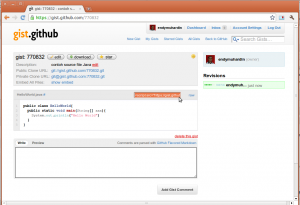
Nanti akan muncul textfield berisi tag HTML untuk dipasang di blog, kira-kira seperti ini tagnya:
<script src="https://gist.github.com/770832.js?file=HelloWorld.java"></script>
Tag ini bisa langsung dipasang di blog kita. Hasilnya seperti di bawah ini.
Kelemahan cara ini adalah dia membutuhkan javascript, dan isi filenya tidak terindeks oleh spider. Untuk mengatasinya, kita gunakan plugin wordpress ini.
Setelah digunakan, kita cukup memasang tag khusus seperti dijelaskan di websitenya. Ini contoh hasilnya
[gist id=770832]
Sekilas tidak terlihat bedanya antara pakai plugin dan tidak. Tapi coba lihat source halaman ini, klik kanan kemudian View Source. Yang menggunakan plugin, source codenya benar-benar ada tulisannya. Sedangkan yang pakai tag script tidak ada source code hello worldnya.
Nah, kalau sudah pakai ini, tidak perlu bingung lagi mewarnai source code di blog. Kalau mau revisi, tinggal edit aja di Github, dan otomatis di blog langsung terupdate.
07 Jan 2011
Setelah kemarin kita bahas migrasi di sisi server, sekarang kita bahas instalasi di client. Kenapa yang dijelaskan hanya Windows, sedangkan Linux tidak? Well, ini karena di Linux instalasinya begitu mudah sehingga terlalu pendek kalau ingin dijadikan satu posting sendiri.
Gak percaya? Ini caranya install di Ubuntu. Buka command prompt, dan ketik
sudo apt-get install git-core git-svn git-gui gitk
Sedikit konfigurasi standar.
git config --global user.name "Endy Muhardin"
git config --global user.email "endy.muhardin@geemail.com"
git config --global color.ui "true"
Kemudian, bila kita belum punya public key, silahkan bikin seperti tutorial di sini.
Dan selesailah sudah. Seperti saya bilang sebelumnya, singkat dan sama sekali gak seru. Gak ada screenshotnya :D
Nah, mari kita bahas instalasi di Windows.
Pertama, unduh Git dari websitenya. Pastikan kita mengambil yang sesuai dengan arsitektur komputer kita (32 bit atau 64 bit).
Setelah diunduh, tentu kita jalankan. Berikut screenshot next-next seperti biasa.

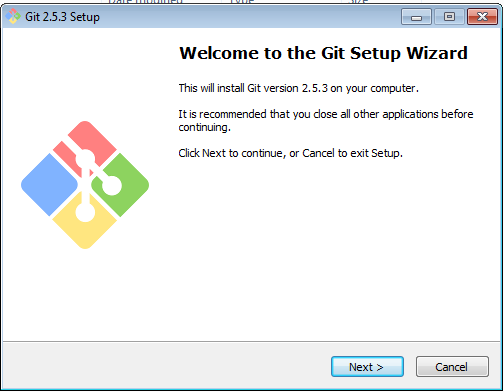

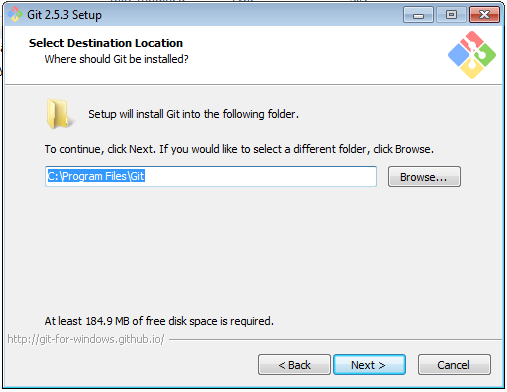


Perhatikan, untuk langkah selanjutnya, kita perlu mengganti opsi default menjadi pilihan yang kedua.

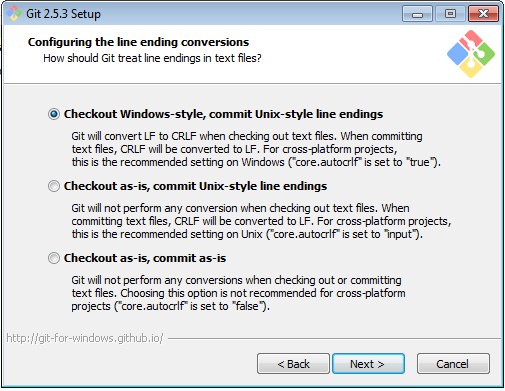
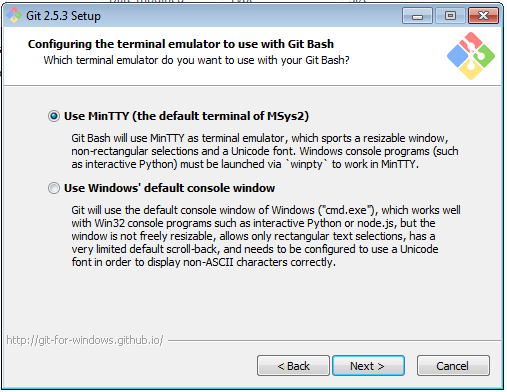



Sampai di sini, instalasi Git sebetulnya sudah selesai. Tapi kita perlu membuat pasangan public dan private key supaya bisa mengakses Github, Bitbucket, atau provider lain melalui protokol SSH. Dengan menggunakan protokol SSH, kita tidak perlu mengetik username/password setiap melakukan sinkronisasi dengan remote repository.
Membuat Key Pair
Pertama, kita jalankan dulu Git Bash. Ini akan membuka command prompt khusus yang disediakan Git.

Selanjutnya, jalankan perintah ssh-keygen. Kita akan ditanyai nama file yang akan dibuat. Ikuti saja defaultnya, yaitu id_rsa untuk private key, dan id_rsa.pub untuk public key.
Kita juga akan dimintai password untuk membuka private key. Tekan Enter bila tidak mau pakai password.

Selanjutnya, kita akan menemui kedua file private dan public key di folder C:\Users\namauser\.ssh seperti ini.

Kedua file bisa dibuka dengan text editor. Yang perlu kita buka hanyalah public key saja.

Isi public key ini nantinya akan kita pasang di Github
Clone dari Github
Untuk bisa clone dari github, pertama kali kita harus punya account Github. Silahkan daftar dulu.
Setelah punya account, login, dan kita akan melihat dashboard.
Klik account setting, dan masuk ke menu SSH Public Keys
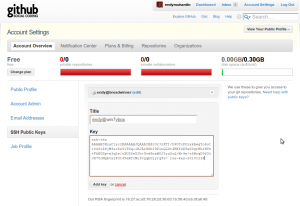
Pastekan public key yang sudah kita generate pada langkah sebelumnya. Setelah diadd, public key kita akan terdaftar. Kita boleh pasang public key banyak-banyak, karena biasanya satu public key mencerminkan satu komputer. Bisa saja kita punya PC dan juga Laptop.
Setting Public Key di Bitbucket
Selain Github, provider lain yang juga populer adalah Bitbucket. Untuk mendaftarkan public key di Bitbucket, kita bisa akses menu di kanan atas, yang ada gambar avatar kita.

Pilih Bitbucket Settings, kita akan mendapatkan halaman Settings

Klik SSH Keys di kiri bawah. Kita akan mendapati halaman untuk menambah SSH Keys.
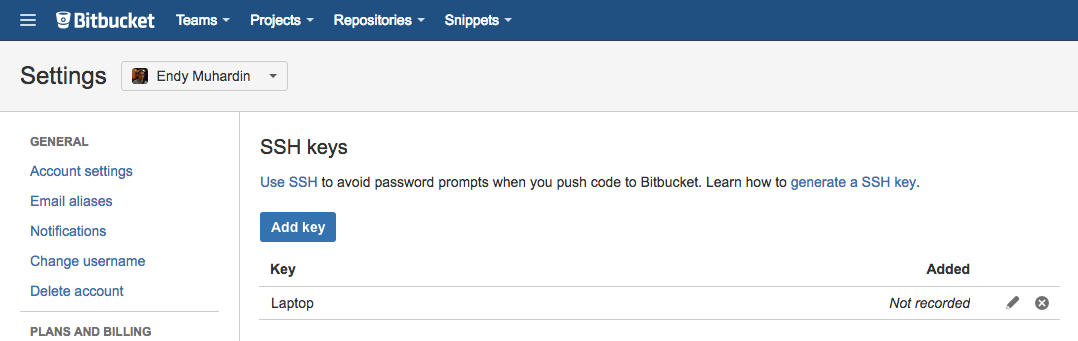
Klik Add Key untuk menambah public key SSH. Selanjutnya, copy dan paste isi public key kita ke kotak yang disediakan.
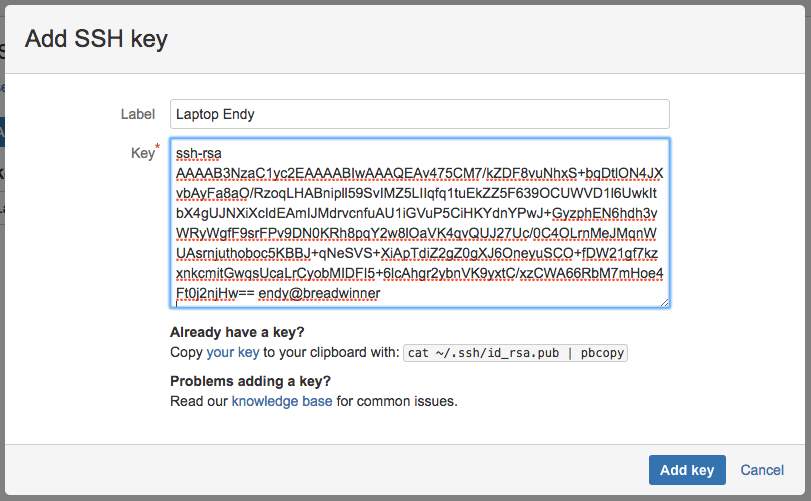
Klik Save, dan public key kita sudah terdaftar

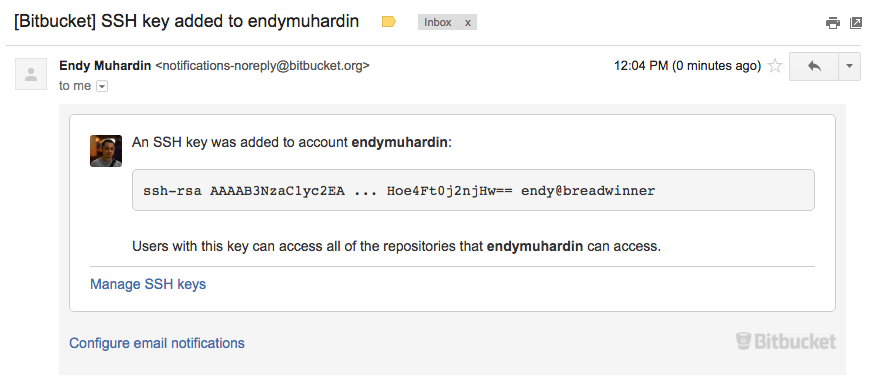
Kita juga akan mendapatkan notifikasi lewat email bahwa ada SSH key baru yang didaftarkan
Mengunduh Isi Repository
Setelah public key didaftarkan, selanjutnya kita lihat repository yang kita punya.
Kalau belum punya repository, Anda bisa fork repository belajarGit punya saya, sehingga nanti Anda punya repo belajarGit sendiri.
Perintahnya adalah sebagai berikut (jalankan dari command line)
git clone git@github.com:endymuhardin/belajarGit.git
Sekarang repository sudah ada di local, dan siap digunakan. Bagaimana cara menggunakannya, stay tuned. Akan dibahas di posting berikutnya.
03 Jan 2011
Di tahun yang baru ini, kami di ArtiVisi juga beralih menggunakan version control baru, yaitu Git.
Menggantikan Subversion yang sudah kita gunakan sejak 2008.
Ada banyak keunggulan Git dibandingkan Subversion, diantaranya:
-
offline operation. Git adalah distributed/decentralized version control system (DVCS), artinya tidak membutuhkan server terpusat untuk bisa bekerja. Keunggulan ini berakibat pada keunggulan berikutnya, yaitu:
-
commit sesuai task, bukan sesuai koneksi internet. Dulu, karena koneksi internet terbatas, programmer commit hanya pada saat ada internet. Akibatnya satu commit berisi perubahan untuk banyak task, tercampur aduk tidak jelas peruntukannya. DVCS memungkinkan programmer untuk commit walaupun tidak ada koneksi internet, dan melakukan sinkronisasi pada saat offline.
-
fitur staging area di Git, memungkinkan kita untuk mengatur isi commit secara detail.
-
fitur rebase untuk mengatur commit. Commit yang teratur akan memudahkan review.
-
branch dan merge yang lebih baik daripada subversion. Karena branch dan merge mudah, maka kita bisa menerapkan berbagai teknik workflow dalam mengelola development.
-
website social coding. Github dan Gitorious merupakan Facebook-nya para programmer. Untuk bisa terlibat di dalamnya, terlebih dulu kita harus bisa Git.
Selain Git, ada juga DVCS lain seperti Mercurial (hg), Bazaar (bzr), dsb. Git dipilih karena :
-
popularitas. Semakin populer, tutorial dan aplikasi pendukung semakin banyak, sehingga semakin nyaman digunakan. Saat ini yang paling populer cuma dua, yaitu git dan hg.
-
local/named branch. Ini fitur penting, tapi entah kenapa tidak ada di core hg. Sepertinya ada di extension, tapi yang jelas merupakan workaround dan bukan didesain sejak awal. Tanpa named branch, pilihan workflow menjadi terbatas.
-
Social coding Git (Github dan Gitorious) jauh lebih superior daripada Mercurial (Bitbucket)
Beberapa faktor di atas adalah alasan kenapa Git yang dipilih.
Baiklah, sekarang saatnya migrasi. Kita akan mengkonversi repository Subversion menjadi repository Git.
Berikut langkah-langkah yang akan kita lakukan:
-
Dump repository Subversion
-
Restore lagi di laptop supaya cepat
-
Buat authorsfile
-
Buat ignore file
-
Clone tanpa metadata
-
Konversi branch
-
Konversi tags
-
Clone hasil konversi menjadi bare repository
Dump repository Subversion
Seperti biasa, sebelum melakukan apapun, lakukan backup dulu. Just in case.
Perintahnya gampang.
svnadmin dump /path/ke/repository | bzip2 -c9 > dump-repository-yyyyMMdd.dmp.bz2
Restore lagi di laptop/PC supaya cepat
Langkah ini optional, kalau kita ingin melakukannya di komputer kita sendiri, bukan di server.
Tapi sebaiknya dilakukan, karena nanti kita akan checkout beberapa kali yang pasti membutuhkan waktu lama jika dilakukan ke server.
Perintah restore gampang.
bzcat dump-repository-yyyyMMdd.dmp.bz2 | svnadmin load /path/ke/repo/svn/di/lokal
Buat authorsfile
Setelah kita memiliki repository Subversion, kita perlu mengambil daftar nama orang-orang yang pernah commit. Ini akan kita butuhkan pada waktu konversi. Nama committer ini diambil dari hasil checkout Subversion. Jadi mari kita checkout dulu.
svn checkout file:///path/ke/repo/svn/di/lokal checkout-project-svn
Karena lokal, harusnya hanya membutuhkan beberapa menit saja.
Setelah dilakukan checkout, kita membutuhkan script untuk mengambil nama committer. Berikut isi scriptnya, simpan saja dengan nama extract-svn-authors.sh
#!/usr/bin/env bash
authors=$(svn log -q | grep -e '^r' | awk 'BEGIN { FS = "|" } ; { print $2 }' | sort | uniq)
for author in ${authors}; do
echo "${author} = NAME <USER@DOMAIN>";
done
Jalankan script tersebut di dalam folder hasil checkout.
cd checkout-project-svn
sh /path/ke/script/extract-svn-authors.sh > nama-committers.txt
Ini akan menghasilkan file nama-committers.txt yang berisi nama committer seperti ini :
endy = NAME <USER@DOMAIN>
Editlah file ini supaya mencerminkan nama dan email yang benar, seperti ini :
endy = Endy Muhardin <endy.muhardin@geemail.com>
Buat ignore file
Dalam mengerjakan project, ada file-file yang ada di folder kerja, tapi tidak kita masukkan ke repository. Misalnya file hasil kompilasi, setting IDE, dan sebagainya. File dan folder hasil generate ini biasanya kita daftarkan di ignore list, supaya tidak ikut dicommit ke repository. Kita perlu mengkonversi format ignore di Subversion (svn property ignore) menjadi format ignore versi Git (yaitu file .gitignore).
Untuk membuatnya, kita clone dulu repository Subversion menjadi repository Git. Ini dilakukan di folder yang berbeda dengan hasil checkout Subversion di langkah sebelumnya.
cd ..
git svn clone --stdlayout -A nama-committers.txt file:///path/ke/repo git-svn-migrasi-project-dengan-metadata
Setelah diclone, konversi ignore list nya.
cd git-svn-migrasi-project-dengan-metadata
git svn show-ignore > .gitignore
Selanjutnya, kita lakukan clone lagi. Kali ini tanpa menyertakan metadata, sehingga hasilnya bersih. Metadata ini digunakan bila kita ingin tetap commit ke repository Subversion, tapi ingin menggunakan Git sebagai frontend.
Perintahnya mirip seperti sebelumnya, kali ini kita tambahkan opsi tanpa metadata.
cd ..
git svn clone --no-metadata --stdlayout -A nama-committers.txt file:///path/ke/repo git-svn-migrasi-project-tanpa-metadata
Ini akan menghasilkan folder git-svn-migrasi-project-tanpa-metadata berisi repository Subversion yang sudah dikonversi menjadi repository Git. Semua langkah selanjutnya akan dilakukan di dalam folder ini.
Setelah selesai, kita masukkan file .gitignore ke repo Git yang baru ini.
cd git-svn-migrasi-project-tanpa-metadata
cp ../git-svn-migrasi-project-dengan-metadata/.gitignore ./
git add .
git commit -m "add ignore list"
Konversi branch
Branch yang ada di Subversion harus kita konversi menjadi branch di Git.
Berikut perintahnya.
git branch -r | grep -v tags | sed -rne 's, *([^@]+)$,\1,p' | while read branch; do echo "git branch $branch $branch"; done | sh
Verifikasi hasilnya dengan perintah ini.
Seharusnya semua branch yang ada di repository Subversion akan terlihat di dalam repository Git ini.
Lakukan perintah berikut untuk mengkonversi tag Subversion menjadi tag Git.
git branch -r | sed -rne 's, *tags/([^@]+)$,\1,p' | while read tag; do echo "git tag $tag 'tags/${tag}^'; git branch -r -d tags/$tag"; done | sh
Verifikasi dengan perintah ini
Pastikan semua tag yang tadinya ada di repository Subversion sudah terdaftar di repository Git.
Clone hasil konversi menjadi bare repository
Setelah nama committer, ignore list, branch, dan tags berhasil kita pindahkan, inilah langkah terakhir. Kita clone sekali lagi menjadi repository bare supaya bisa dishare dengan orang lain. Biasanya repository bare ini kita publish dengan Gitosis, gitweb, atau aplikasi server lainnya.
Perintah ini dilakukan di luar repository Git yang kita gunakan pada langkah sebelumnya.
cd ..
git clone --bare git-svn-migrasi-project-tanpa-metadata nama-project.git
Ini akan menghasilkan satu folder dengan nama nama-project.git berisi repository Git yang siap dishare.
Demikian posting tahun baru. Semoga kita semua lebih sukses di tahun 2011 ini.
07 Jul 2010
Pada waktu kita melakukan requirement gathering, harapan kita adalah agar requirement yang kita dapatkan di fase requirement tidak jauh bergeser dari requirement final setelah project closing. Kalau pergeserannya jauh, akan mengakibatkan waktu dan biaya pengerjaan project menjadi molor dan akibatnya kedua belah pihak akan dirugikan.
Pergeseran requirement ini bisa disebabkan beberapa hal, misalnya :
-
business analyst (BA) kurang pengalaman, sehingga tidak bisa mengidentifikasi varian-varian skenario. Akibatnya terjadi banyak ‘hidden requirement’
-
business analyst kurang teliti, sehingga salah memahami penjelasan user
-
Perubahan bisnis client, sehingga requirementnya juga berubah
-
perbedaan persepsi antara user dan analyst atau programmer
Untuk masalah 1 dan 2, solusinya adalah dengan mengganti BA dengan orang yang lebih berpengalaman. Newbie sebaiknya tidak menjadi BA. Bolehlah magang BA, tapi jangan diandalkan untuk jadi BA utama.
Poin 3 juga biasanya tidak masalah. Client biasanya cukup tahu diri kalau terjadi hal ini, sehingga tidak keberatan dimintai charge tambahan.
Nah untuk poin 4, biasanya sulit dideteksi sampai aplikasi kita deliver. Sering terjadi, usernya OK OK saja pada fase requirement, dan tiba-tiba pada waktu kita deliver aplikasinya, dia langsung bingung karena aplikasinya ‘aneh’.
Agar poin 4 ini tidak terjadi, sebaiknya kita melakukan prototyping. Bagaimana cara melakukan prototyping yang baik?
Prototyping itu idealnya :
-
Murah meriah dan cepat
Dalam 1 hari kita harus bisa menggambar minimal 10 screen.
Begitu usernya selesai ngomong/gambar di papan tulis, screennya juga harus langsung jadi.
Jangan sampai effort untuk prototyping lebih besar dari effort untuk coding.
-
Gampang diubah
Tujuan prototype adalah supaya user bisa merasakan seperti apa aplikasinya nanti.
Kalau dirasakan kurang sesuai, tentunya dia ingin mengubahnya.
Nah, jangan sampai minta geser tombol aja harus nunggu 30 menit.
-
Mirip aslinya.
Kalo ini lebih ke sisi development.
Biar efisien, begitu prototype sign off, kita bisa mulai paralel coding dan bikin user manual.
Kalo prototypenya udah bener2 mirip, bisa langsung discreenshot dan dipasang di user manual.
Jadi begitu aplikasi jadi, user manual juga selesai.
-
Terlihat belum selesai
Ini agak kontradiktif dengan tips #3. Kalau prototype kita sangat mirip aplikasi betulan, client akan memiliki persepsi bahwa aplikasinya sudah hampir selesai. Padahal belum ada coding sama sekali. Oleh karena itu, sangat penting kita tekankan ke client bahwa masih ada jangka waktu yang lama sebelum aplikasi betulannya selesai.
Ada beberapa tools yang bisa digunakan untuk prototyping, yaitu
Untuk project aplikasi desktop, inilah yang biasa kami gunakan di ArtiVisi. Screen dapat dibuat dengan sangat cepat, lengkap dengan behavior standar seperti popup dialog, scroll table, dsb.
Untuk project web, biasanya kita langsung coding di HTML dan Dojo, tentunya tanpa koneksi ke back end.
Sebagai nilai tambah lain, setelah prototype di-approve client, programmer bisa langsung meneruskan coding.
Tools ini berbayar dan dijalankan menggunakan Adobe AIR.
Pencil
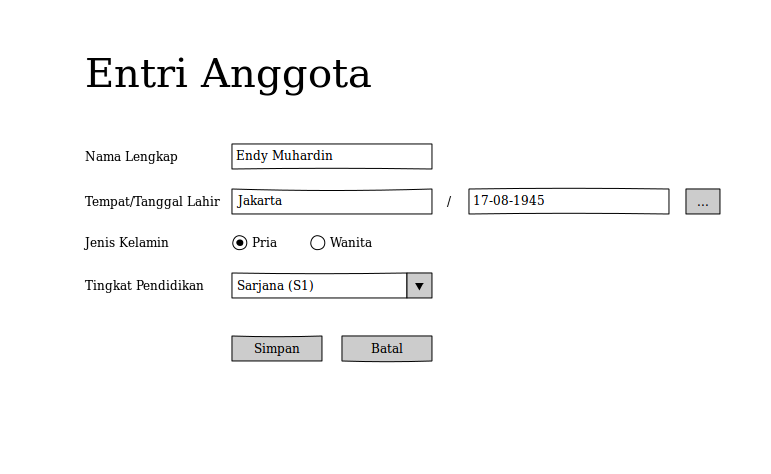
Tools ini lumayan bagus, dijalankan sebagai Firefox Add Ons. Sudah ada palette untuk berbagai UI component seperti combo box, text area, dsb. Setelah selesai menggambar, kita bisa langsung mengekspornya menjadi image.
Berikut contoh mockup yang baru saja saya buat menggunakan Pencil.
Ini versi ‘bagus’ yang mirip aslinya.

Supaya client sadar bahwa ini adalah prototype, kita bisa gunakan versi yang coret-coretan.
Source file untuk mockup di atas bisa diunduh di sini.
Demikianlah sedikit tips dan trik. Semoga bermanfaat.
30 Jun 2010
Suatu aplikasi, walaupun sudah go-live di environment production, tetap bisa saja mengalami error dan bug. Bug ini seringkali tidak ditemukan di environment development karena berbagai hal, misalnya variasi data, jumlah data, dan sebagainya.
Langkah pertama ketika kita mengetahui ada bug tentunya adalah melokalisir masalah. Pada kondisi mana saja bug tersebut muncul. Setelah itu, kita dapat memfokuskan pencarian masalah di lokasi tersebut. Ini lebih efisien daripada kita harus menelusuri keseluruhan sistem.
Misalnya kita sudah berhasil melokalisir masalah, yaitu transaksi di bulan tertentu. Langkah selanjutnya adalah memindahkan data production di lokasi tersebut ke environment development. Ini kita lakukan supaya kita bebas bereksperimen dengan data tersebut tanpa khawatir membahayakan data production.
Masalahnya, tools backup database yang tersedia biasanya tidak bisa digunakan untuk mengambil sebagian data. Walaupun bisa (mysqldump menyediakan opsi where untuk membatasi record yang diambil), biasanya terbatas hanya di satu tabel saja. Sedangkan untuk bisa merestore-nya di development, kita butuh semua relasinya.
Sebagai contoh, coba lihat skema berikut.
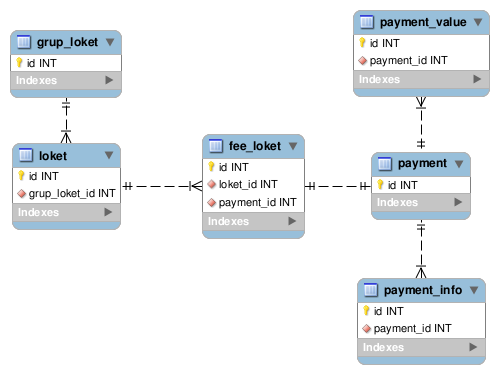
Untuk mengambil data payment, tentunya kita juga harus menarik data lain yang berelasi dengannya, yaitu di tabel grup loket, loket, payment value, payment info dan fee loket. Ini sangat sulit dilakukan, apalagi kalau data payment tersebut jumlahnya ratusan ribu record.
Untunglah ada tools untuk mengatasi masalah ini, namanya Jailer. Dengan menggunakan Jailer, kita dapat menentukan tabel mana yang akan diambil datanya (payment), kriteria pengambilan (bulan tertentu saja), dan relasi mana saja yang ingin kita ambil. Hasilnya adalah satu set data lengkap dengan dependensinya yang bisa kita restore di development.
Persiapan Jailer
Pertama, tentunya kita unduh dulu Jailer di websitenya. Jangan lupa teriakkan, “Hidup Open Source !!!”, karena aplikasi ini tersedia secara gratis berkat gerakan open source.
Setelah berhasil diunduh, extract ke folder tertentu. Jailer tidak menyertakan driver untuk koneksi ke database, sehingga kita harus sediakan sendiri. Karena saya menggunakan MySQL, saya masukkan file mysql-connector.jar ke dalam folder lib. Kita mengikutkan driver database ke folder Jailer karena nantinya folder ini akan kita pack dan upload ke server production.
Jailer ini akan kita jalankan di mesin development yang sudah terisi skema database. Kita akan coba dulu ambil data di development, kalau sudah sukses baru kita jalankan di production.
Ada dua script untuk menjalankan jailer, yaitu jailerGUI dan jailer. jailerGUI digunakan untuk mendesain pengambilan data, sedangkan jailer adalah antarmuka command line untuk menjalankan pengambilan data. Karena kita ingin mendesain proses pengambilannya, kita gunakan jailerGUI.
Berikut adalah tampilan awal Jailer.
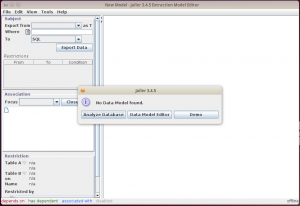
Jailer memberitahu kita bahwa belum ada data model yang bisa dikerjakan, dan menyarankan kita untuk menganalisa database. Klik Analyze Database. Selanjutnya Jailer akan meminta informasi cara koneksi ke database.

Isikan informasi koneksi database dan driver yang digunakan. Driver yang kita gunakan adalah yang tadi sudah kita copy ke folder lib.
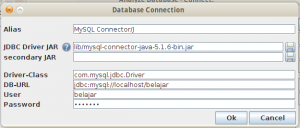
Klik OK untuk menganalisa database.
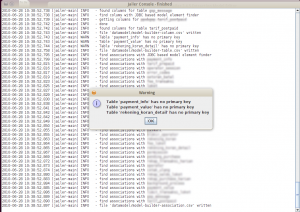
Setelah itu, Jailer akan menghubungi database untuk mengambil informasi. Lognya akan ditampilkan di log output. Jailer akan memberi tahu kita tabel-tabel yang tidak ada primary keynya. Jailer tidak dapat memproses tabel tanpa primary key.
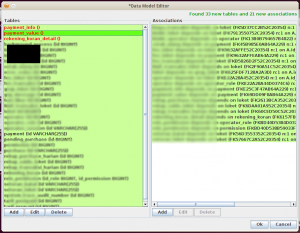
Klik tabel yang berwarna merah, dan definisikan primary keynya. Primary key yang kita definisikan di sini hanya digunakan Jailer, sehingga tidak perlu khawatir skema aslinya akan berubah.
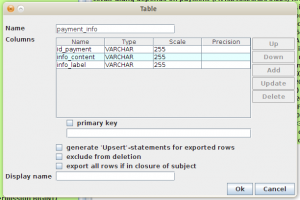
Setelah itu, klik OK. Jailer akan menampilkan screen Extraction Model Editor. Pilih tabel payment, di dropdown subject, karena inilah tabel yang akan kita gunakan sebagai pusat extraction.
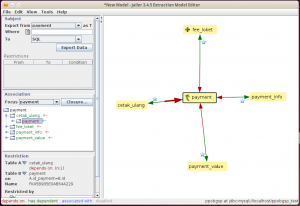
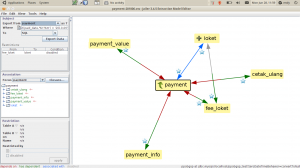
Jailer mendeteksi relasi antar tabel berdasarkan constraint foreign key yang kita pasang di database. Kadangkala ada tabel-tabel yang berelasi, namun tidak ada constraintnya. Entah karena malas mendefinisikan, atau memang sengaja tidak dikaitkan. Kita bisa mendaftarkan relasi tanpa constraint ini dengan membuka lagi Data Model Editor, kemudian klik Add di kotak Association sebelah kanan.

Setelah diklik OK, maka skema relasi di Extraction Model Editor akan berubah sesuai relasi yang ditambahkan. Sama dengan definisi primary key di atas, relasi ini hanya disimpan oleh Jailer dan tidak diaplikasikan ke skema database.
Kita perlu mendefinisikan batasan record payment yang akan diambil, yaitu yang terjadi di bulan Juni 2010. Dalam bentuk SQL, berikut adalah query yang digunakan
select * from payment where date_format(paid_date, '%Y-%m') = '2010-06'
Kita ambil expression setelah where dan pasang di textfield where dalam Extraction Model Editor.
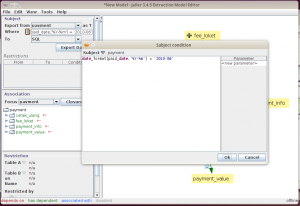
Simpan dulu extraction modelnya.
Beri nama yang representatif, misalnya payment-201006. Jailer akan menyimpan extraction model ini dalam format csv. Kalau sudah memahami formatnya, kita bisa membuatnya dengan text editor tanpa GUI (kalau mau).
Setelah tersimpan, kita bisa klik Export Data sehingga memunculkan dialog berikut.
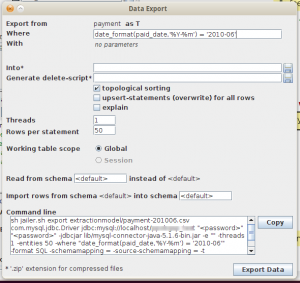
Di screen tersebut kita bisa mengatur konfigurasi pengambilan data. Bagi saya, nilai defaultnya sudah memadai sehingga tidak ada yang diubah.
Di box paling bawah ada command line yang bisa kita copy-paste untuk dijalankan tanpa GUI. Copy saja isinya ke text file untuk digunakan nanti.
Yang harus kita isi di screen ini adalah textfield Into. Ini adalah nama file yang akan menampung script SQL berisi data yang diinginkan. Isi saja dengan nama payment-201006.sql.
Setelah itu, klik Export Data. Jailer akan segera bekerja dan menampilkan hasilnya dalam bentuk tree.
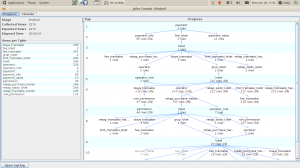
Di situ kita bisa lihat berapa row yang akan diambil dari masing-masing tabel.
Seperti kita lihat, cukup signifikan, yaitu 2000an record. Ini disebabkan karena jailer mengambil record secara rekursif tanpa ada batasan.
Setelah dianalisa, kita hanya ingin mengambil tabel-tabel yang berkaitan langsung, yaitu payment, payment_info, payment_value, dan fee_loket. Sedangkan tabel sisanya dapat diabaikan karena bersifat pelengkap atau master data yang sudah ada di database development.
Dengan melihat ke tree-nya, kita bisa memutus relasi fee_loket ke loket, karena dari situlah semua data lain akan ikut terbawa.
Tutup screennya, dan kembali ke Extraction Model Editor.
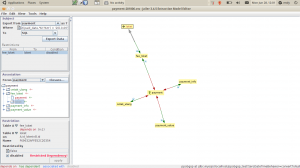
Di kotak Association, expand node yang ingin kita putuskan, yaitu fee loket. Klik relasi loket, dan centang checkbox disabled di pojok kiri bawah. Setelah itu, jalankan lagi Export Data.
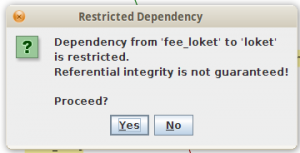
Jailer akan mengingatkan bahwa dengan membatasi dependensi, referential integrity akan rusak, karena relasi foreign key dari fee_loket ke loket akan terputus. Klik saja Yes, karena di database development kita tabel loket sudah terisi lengkap.
Inilah hasilnya
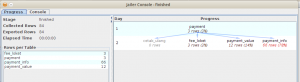
Seperti kita lihat di atas, kita cuma mendapatkan 84 record dan pengambilan data berhenti di tabel fee_loket.
Periksa output payment-201006.sql di folder Jailer untuk memastikan hasilnya sudah benar.
Setelah sukses dijalankan di database development, compress lagi jailer yang sudah dimodifikasi barusan dan upload ke server production. Setibanya di server production, extract, kemudian jalankan script yang tadi kita copy-paste.
Kalau baru pertama kali dijalankan, script ini akan menimbulkan error sebagai berikut :
$ ./export-payment-201006.sh
2010-06-28 14:15:08,114 [main] INFO - Jailer 3.4.5
2010-06-28 14:15:08,117 [main] INFO - added 'lib/mysql-connector-java-5.1.6-bin.jar' to classpath
2010-06-28 14:15:08,119 [main] INFO - exporting 'extractionmodel/payment-201006.csv' to 'payment-201006.sql'
2010-06-28 14:15:08,700 [main] INFO - begin guessing SQL dialect
2010-06-28 14:15:08,711 [main] INFO - end guessing SQL dialect
2010-06-28 14:15:08,718 [main] ERROR - Can't find working tables! Run 'bin/jailer.sh create-ddl' and execute the DDL-script first!
java.lang.RuntimeException: Can't find working tables! Run 'bin/jailer.sh create-ddl' and execute the DDL-script first!
at net.sf.jailer.entitygraph.EntityGraph.create(EntityGraph.java:122)
at net.sf.jailer.Jailer.export(Jailer.java:1142)
at net.sf.jailer.Jailer.jailerMain(Jailer.java:1064)
at net.sf.jailer.Jailer.jailerMain(Jailer.java:989)
at net.sf.jailer.Jailer.main(Jailer.java:967)
Caused by: java.sql.SQLException: "Table 'ppobgsp_test.JAILER_GRAPH' doesn't exist" in statement "Insert into JAILER_GRAPH(id, age) values (2104021762, 1)"
at net.sf.jailer.database.Session.executeUpdate(Session.java:470)
at net.sf.jailer.entitygraph.EntityGraph.create(EntityGraph.java:120)
... 4 more
Error: java.lang.RuntimeException: Can't find working tables! Run 'bin/jailer.sh create-ddl' and execute the DDL-script first!
2010-06-28 14:15:08,724 [main] ERROR - working directory is /opt/downloads/java/tools/test/integration-test/jailer
Ini disebabkan karena Jailer ternyata membuat beberapa tabel di database untuk kebutuhan internalnya. Ini dapat dilihat pada database development kita.
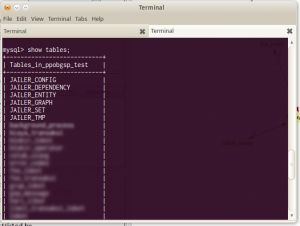
Untuk menggenerate tabel di atas, kita jalankan jailer dengan opsi create-ddl. Ini akan menghasilkan SQL di layar. SQL ini harus kita jalankan di database production supaya tabelnya terbentuk.
$ sh jailer.sh create-ddl
DROP TABLE JAILER_ENTITY;
DROP TABLE JAILER_DEPENDENCY;
DROP TABLE JAILER_SET;
DROP TABLE JAILER_GRAPH;
DROP TABLE JAILER_CONFIG;
DROP TABLE JAILER_TMP;
CREATE TABLE JAILER_CONFIG
(
jversion VARCHAR(20),
jkey VARCHAR(200),
jvalue VARCHAR(200)
) ;
INSERT INTO JAILER_CONFIG(jversion, jkey, jvalue) values('3.4.5', 'magic', '837065098274756382534403654245288');
CREATE TABLE JAILER_GRAPH
(
id INTEGER NOT NULL,
age INTEGER NOT NULL
-- ,CONSTRAINT jlr_pk_graph PRIMARY KEY(id)
) ;
CREATE TABLE JAILER_ENTITY
(
r_entitygraph INTEGER NOT NULL,
PK0 BIGINT , PK1 VARCHAR(255) , PK2 VARCHAR(255) , PK3 INT , PK4 VARCHAR(255) , PK5 BIGINT ,
birthday INTEGER NOT NULL,
type VARCHAR(120) NOT NULL,
PRE_PK0 BIGINT , PRE_PK1 VARCHAR(255) , PRE_PK2 VARCHAR(255) , PRE_PK3 INT , PRE_PK4 VARCHAR(255) , PRE_PK5 BIGINT ,
PRE_TYPE VARCHAR(120),
orig_birthday INTEGER,
association INTEGER
-- , CONSTRAINT jlr_fk_graph_e FOREIGN KEY (r_entitygraph) REFERENCES JAILER_GRAPH(id)
) ;
CREATE INDEX jlr_enty_brthdy ON JAILER_ENTITY (r_entitygraph, birthday, type) ;
CREATE INDEX jlr_enty_upk1 ON JAILER_ENTITY (r_entitygraph , PK0, PK1, PK2, PK3, PK4, PK5, type) ;
CREATE TABLE JAILER_SET
(
set_id INTEGER NOT NULL,
type VARCHAR(120) NOT NULL,
PK0 BIGINT , PK1 VARCHAR(255) , PK2 VARCHAR(255) , PK3 INT , PK4 VARCHAR(255) , PK5 BIGINT
) ;
CREATE INDEX jlr_pk_set1 ON JAILER_SET (set_id , PK0, PK1, PK2, PK3, PK4, PK5, type) ;
CREATE TABLE JAILER_DEPENDENCY
(
r_entitygraph INTEGER NOT NULL,
assoc INTEGER NOT NULL,
depend_id INTEGER NOT NULL,
traversed INTEGER,
from_type VARCHAR(120) NOT NULL,
to_type VARCHAR(120) NOT NULL,
FROM_PK0 BIGINT , FROM_PK1 VARCHAR(255) , FROM_PK2 VARCHAR(255) , FROM_PK3 INT , FROM_PK4 VARCHAR(255) , FROM_PK5 BIGINT ,
TO_PK0 BIGINT , TO_PK1 VARCHAR(255) , TO_PK2 VARCHAR(255) , TO_PK3 INT , TO_PK4 VARCHAR(255) , TO_PK5 BIGINT
-- , CONSTRAINT jlr_fk_graph_d FOREIGN KEY (r_entitygraph) REFERENCES JAILER_GRAPH(id)
) ;
CREATE INDEX jlr_dep_from1 ON JAILER_DEPENDENCY (r_entitygraph, assoc , FROM_PK0, FROM_PK1, FROM_PK2, FROM_PK3, FROM_PK4, FROM_PK5) ;
CREATE INDEX jlr_dep_to1 ON JAILER_DEPENDENCY (r_entitygraph , TO_PK0, TO_PK1, TO_PK2, TO_PK3, TO_PK4, TO_PK5) ;
CREATE TABLE JAILER_TMP
(
c1 INTEGER,
c2 INTEGER
) ;
INSERT INTO JAILER_CONFIG(jversion, jkey, jvalue) values('3.4.5', 'upk', '679547784');
Setelah tabelnya siap, jalankan kembali script yang error di atas. Berikut outputnya.
$ ./export-payment-201006.sh
2010-06-28 14:12:31,175 [main] INFO - Jailer 3.4.5
2010-06-28 14:12:31,190 [main] INFO - added 'lib/mysql-connector-java-5.1.6-bin.jar' to classpath
2010-06-28 14:12:31,191 [main] INFO - exporting 'extractionmodel/payment-201006.csv' to 'payment-201006.sql'
2010-06-28 14:12:32,850 [main] INFO - SQL dialect is MYSQL
2010-06-28 14:12:32,925 [main] INFO - gather statistics after 0 inserted rows...
2010-06-28 14:12:32,966 [main] INFO - reading file 'renew.sql'
2010-06-28 14:12:32,966 [main] INFO - 0 statements (100%)
2010-06-28 14:12:32,967 [main] INFO - successfully read file 'renew.sql'
2010-06-28 14:12:32,977 [main] INFO - exporting payment Where date_format(paid_date,'%Y-%m') = '2010-06'
2010-06-28 14:12:33,028 [main] INFO - day 1, progress: payment
2010-06-28 14:12:33,039 [main] INFO - starting 4 jobs
2010-06-28 14:12:33,040 [main] INFO - gather statistics after 3 inserted rows...
2010-06-28 14:12:33,041 [main] INFO - reading file 'renew.sql'
2010-06-28 14:12:33,042 [main] INFO - 0 statements (100%)
2010-06-28 14:12:33,042 [main] INFO - successfully read file 'renew.sql'
2010-06-28 14:12:33,047 [main] INFO - resolving payment -> payment_info (inverse-FKE25C3F47AB64A229) 1:n on B.id_payment=A.id...
2010-06-28 14:12:33,105 [main] INFO - 66 entities found resolving payment -> payment_info (inverse-FKE25C3F47AB64A229) 1:n on B.id_payment=A.id
2010-06-28 14:12:33,105 [main] INFO - resolving payment -> cetak_ulang (inverse-FK45B985E0AB64A229) 1:n on B.id_payment=A.id...
2010-06-28 14:12:33,126 [main] INFO - 0 entities found resolving payment -> cetak_ulang (inverse-FK45B985E0AB64A229) 1:n on B.id_payment=A.id
2010-06-28 14:12:33,126 [main] INFO - resolving payment -> fee_loket (inverse-FK9632AFFEAB64A229) 1:n on B.id_payment=A.id...
2010-06-28 14:12:33,129 [main] INFO - 3 entities found resolving payment -> fee_loket (inverse-FK9632AFFEAB64A229) 1:n on B.id_payment=A.id
2010-06-28 14:12:33,131 [main] INFO - resolving payment -> payment_value (inverse-FK69DD09F8AB64A229) 1:n on B.id_payment=A.id...
2010-06-28 14:12:33,142 [main] INFO - 12 entities found resolving payment -> payment_value (inverse-FK69DD09F8AB64A229) 1:n on B.id_payment=A.id
2010-06-28 14:12:33,143 [main] INFO - executed 4 jobs
2010-06-28 14:12:33,143 [main] INFO - day 2, progress: payment_info, fee_loket, payment_value
2010-06-28 14:12:33,144 [main] INFO - skip reversal association payment_info -> payment
2010-06-28 14:12:33,144 [main] INFO - skip reversal association fee_loket -> payment
2010-06-28 14:12:33,147 [main] INFO - skip reversal association payment_value -> payment
2010-06-28 14:12:33,147 [main] INFO - starting 1 jobs
2010-06-28 14:12:33,148 [main] INFO - executed 1 jobs
2010-06-28 14:12:33,149 [main] INFO - exported payment Where date_format(paid_date,'%Y-%m') = '2010-06'
2010-06-28 14:12:33,149 [main] INFO - total progress: payment_info, payment, fee_loket, payment_value
2010-06-28 14:12:33,149 [main] INFO - export statistic:
2010-06-28 14:12:33,169 [main] INFO - Exported Rows: 84
2010-06-28 14:12:33,169 [main] INFO - fee_loket 3
2010-06-28 14:12:33,169 [main] INFO - payment 3
2010-06-28 14:12:33,172 [main] INFO - payment_info 66
2010-06-28 14:12:33,172 [main] INFO - payment_value 12
2010-06-28 14:12:33,173 [main] INFO - writing file 'payment-201006.sql'...
2010-06-28 14:12:33,178 [main] INFO - independent tables: payment
2010-06-28 14:12:33,179 [main] INFO - starting 1 jobs
2010-06-28 14:12:33,380 [main] INFO - executed 1 jobs
2010-06-28 14:12:33,380 [main] INFO - independent tables: payment_info, fee_loket, payment_value
2010-06-28 14:12:33,384 [main] INFO - starting 3 jobs
2010-06-28 14:12:33,447 [main] INFO - executed 3 jobs
2010-06-28 14:12:33,447 [main] INFO - cyclic dependencies for:
2010-06-28 14:12:33,447 [main] INFO - starting 0 jobs
2010-06-28 14:12:33,448 [main] INFO - executed 0 jobs
2010-06-28 14:12:33,448 [main] INFO - gather statistics after 84 inserted rows...
2010-06-28 14:12:33,450 [main] INFO - reading file 'renew.sql'
2010-06-28 14:12:33,450 [main] INFO - 0 statements (100%)
2010-06-28 14:12:33,454 [main] INFO - successfully read file 'renew.sql'
2010-06-28 14:12:33,456 [main] INFO - starting 0 jobs
2010-06-28 14:12:33,467 [main] INFO - executed 0 jobs
2010-06-28 14:12:33,486 [main] INFO - file 'payment-201006.sql' written.
Selesai sudah, data yang kita inginkan ada di file payment-201006.sql, siap diunduh dan dijalankan di database development.
Semoga bermanfaat, kalau ada yang kurang jelas, silahkan baca tutorial resminya.
