26 Aug 2011
Seberapa penting file di komputer kita? Tentu tidak ternilai harganya. Tapi apakah kita melakukan backup secara terhadap file-file di komputer kita? Beberapa menit yang lalu, saya menjawab tidak untuk pertanyaan tersebut.
Kenapa backup tidak dilakukan? Penyebab utamanya biasanya adalah karena merepotkan. Kita harus pilih file yang mau dibackup, membuka aplikasi backup, lalu menjalankannya. Walaupun cuma butuh waktu beberapa menit, tapi biasanya kita sering menunda dan akhirnya lupa.
Cara paling efektif untuk melakukan backup rutin adalah dengan mengotomasinya. Effort untuk melakukan setup cukup sekali saja, selanjutnya backup akan berjalan otomatis tanpa kita sadari. Pada artikel ini, saya akan posting teknik backup yang saya gunakan.
Sebelum kita mulai, terlebih dulu kita tentukan requirementnya, supaya jelas apa yang kita ingin capai. Saya ingin membackup folder tertentu di komputer saya (misalnya /home/endy dan /opt/multimedia/Photos). Backup ini dilakukan secara rutin (misalnya satu jam sekali, satu hari sekali, atau satu minggu sekali). Selain rutin, juga harus incremental. Artinya kalau saya punya backup hari ini jam 11, maka backup selanjutnya di jam 12 hanya menyimpan file yang berubah saja. Dengan demikian, saya bisa jalankan backupnya satu jam sekali dan tidak akan menyebabkan harddisk menjadi penuh dalam beberapa jam saja.
Lanjut membaca ...
16 Aug 2011
Staged Deployment
Pada waktu kita coding, tentunya kita melakukan test terhadap kode program yang kita tulis. Kita jalankan langkah-langkah sesuai yang telah didefinisikan dalam test scenario. Setelah test di komputer kita sendiri (local) selesai dilakukan, tentunya kode program tersebut tidak langsung kita deploy ke production. Best practicesnya adalah, kita deploy aplikasinya ke server testing untuk kemudian ditest oleh Software Tester. Barulah setelah dinyatakan OK oleh tester, aplikasi versi terbaru tersebut kita deploy ke production.
Dengan demikian, kita memiliki tiga deployment environment, yaitu :
Environment ini bisa lebih banyak lagi kalau aplikasi kita harus dites kompatibilitasnya dengan berbagai hardware atau sistem operasi.
Cara kerja seperti ini disebut dengan istilah staged deployment atau deployment bertahap. Dengan menggunakan staged deployment, kita mencegah terjadinya bug fatal di production/live system.
Tantangan yang kita hadapi adalah, bagaimana cara mengelola konfigurasi aplikasi kita sehingga bisa dideploy di berbagai environment secara baik. Teknik bagaimana cara melakukan ini berbeda-beda, tergantung bahasa pemrograman, framework, dan library yang kita gunakan.
Pada artikel ini, kita akan membahas cara mengelola konfigurasi deployment menggunakan teknologi yang biasa digunakan di ArtiVisi, yaituSpring Framework dan Logback.
Alternatif Solusi
Manajemen konfigurasi ini bisa kita lakukan dengan dua pendekatan, yaitu dikelola dengan Maven Profile, atau dengan konfigurasi Spring Framework.
Jika kita menggunakan Maven Profile, kita menambahkan opsi pada saat melakukan build, kira-kira seperti ini :
mvn -P production clean install
atau
mvn -Denv=production clean install
Dalam konfigurasi profile, kita bisa memilih file mana yang akan diinclude di dalam hasil build. Hasilnya, kita bisa menghasilkan artifact yang berbeda tergantung dari opsi yang kita berikan pada saat build.
Walaupun demikian, berdasarkan hasil Googling, ternyata metode ini tidak direkomendasikan. Justru konfigurasi melalui Spring lebih disarankan.
Dengan menggunakan konfigurasi Spring, artifact yang dihasilkan oleh build hanya satu jenis saja. Artifact ini berisi semua pilihan konfigurasi. Konfigurasi mana yang akan aktif pada saat dijalankan (runtime) akan ditentukan oleh setting environment variable, bukan oleh artifactnya.
Selanjutnya, kita akan membahas metode manajemen konfigurasi menggunakan Spring.
Konfigurasi Database
Konfigurasi yang biasanya berbeda adalah informasi koneksi database. Untuk membedakan masing-masing environment, kita akan membuat tiga file, yaitu:
-
jdbc.properties : digunakan di laptop programmer
-
jdbc.testing.properties : digunakan di server test
-
jdbc.production.properties : digunakan di live
Berikut contoh isi jdbc.properties, yaitu konfigurasi koneksi database di laptop saya :
hibernate.dialect = org.hibernate.dialect.MySQL5InnoDBDialect
jdbc.driver = com.mysql.jdbc.Driver
jdbc.url = jdbc:mysql://localhost/kasbon?zeroDateTimeBehavior=convertToNull
jdbc.username = kasbon
jdbc.password = kasbon
Kemudian, ini file jdbc.testing.properties :
hibernate.dialect = org.hibernate.dialect.MySQL5InnoDBDialect
jdbc.driver = com.mysql.jdbc.Driver
jdbc.url = jdbc:mysql://localhost/kasbon_testing?zeroDateTimeBehavior=convertToNull
jdbc.username = root
jdbc.password = admin
Perhatikan bahwa informasi nama database, username, dan password databasenya berbeda dengan yang ada di konfigurasi laptop.
Terakhir, jdbc.production.properties
hibernate.dialect = org.hibernate.dialect.MySQL5InnoDBDialect
jdbc.driver = com.mysql.jdbc.Driver
jdbc.url = jdbc:mysql://localhost/kasbon_live?zeroDateTimeBehavior=convertToNull
jdbc.username = root
jdbc.password = admin
Ketiga file konfigurasi ini akan dibaca oleh konfigurasi Spring, yaitu di file applicationContext.xml. Isi lengkap dari file ini adalah sebagai berikut.
<?xml version="1.0" encoding="UTF-8"?>
<beans xmlns="http://www.springframework.org/schema/beans"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xmlns:context="http://www.springframework.org/schema/context"
xmlns:p="http://www.springframework.org/schema/p" xmlns:tx="http://www.springframework.org/schema/tx"
xsi:schemaLocation="http://www.springframework.org/schema/beans http://www.springframework.org/schema/beans/spring-beans.xsd
http://www.springframework.org/schema/context http://www.springframework.org/schema/context/spring-context.xsd
http://www.springframework.org/schema/tx http://www.springframework.org/schema/tx/spring-tx.xsd">
<context:property-placeholder location="
classpath*:jdbc.properties,
classpath*:jdbc.${stage}.properties
" />
<tx:annotation-driven />
<bean id="dataSource" class="org.apache.commons.dbcp.BasicDataSource"
destroy-method="close" p:driverClassName="${jdbc.driver}" p:url="${jdbc.url}"
p:username="${jdbc.username}" p:password="${jdbc.password}" p:maxWait="40000"
p:maxActive="80" p:maxIdle="20" />
<bean id="transactionManager"
class="org.springframework.orm.hibernate3.HibernateTransactionManager"
p:sessionFactory-ref="sessionFactory" />
<bean id="sessionFactory"
class="org.springframework.orm.hibernate3.annotation.AnnotationSessionFactoryBean"
p:dataSource-ref="dataSource" p:configLocations="classpath*:com/artivisi/**/hibernate.cfg.xml">
<property name="hibernateProperties">
<props>
<prop key="hibernate.dialect">${hibernate.dialect}</prop>
</props>
</property>
</bean>
<bean id="messageSource"
class="org.springframework.context.support.ResourceBundleMessageSource">
<property name="basenames">
<list>
<value>messages</value>
</list>
</property>
</bean>
</beans>
Untuk lebih spesifik, konfigurasinya ada di baris berikut
<context:property-placeholder location="
classpath*:jdbc.properties,
classpath*:jdbc.${stage}.properties
" />
Di sana kita melihat ada variabel ${stage}.
Variabel ${stage} ini akan dicari dari beberapa tempat, diantaranya environment variabel yang bisa diset di JVM ataupun di sistem operasi. Cara mengeset variabel ${stage} akan kita bahas sebentar lagi.
Di situ kita menyuruh Spring untuk membaca file jdbc.properties dan jdbc.${stage}.properties. Jika ada nilai variabel yang sama (misalnya jdbc.username), maka nilai variabel di file yang disebutkan belakangan akan menimpa nilai yang didefinisikan file di atasnya.
Contohnya, misalnya variabel ${stage} nilainya adalah testing. Maka Spring akan membaca file jdbc.properties dan jdbc.testing.properties. Karena kedua file memiliki variabel jdbc.url, maka isi jdbc.url di file jdbc.testing.properties akan menimpa nilai jdbc.url di jdbc.properties.
Bila variabel ${stage} tidak ada isinya, Spring akan mencari file yang namanya jdbc.${stage}.properties, dan tidak akan ketemu. Dengan demikian, nilai yang digunakan adalah yang ada di jdbc.properties.
Dengan demikian, behavior aplikasi adalah sebagai berikut
Bila variabel stage diset production atau testing, maka yang digunakan adalah nilai konfigurasi di jdbc.production.properties atau jdbc.testing.properties. Bila tidak diset atau diset selain itu, maka yang digunakan adalah konfigurasi di jdbc.properties
Behavior seperti inilah yang kita inginkan. Selanjutnya, tinggal kita isi nilai variabel stage.
Setting Environment Variabel
Variabel stage bisa diset dengan berbagai cara. Bila kita menggunakan Apache Tomcat, maka kita mengedit file startup.sh atau startup.bat. Modifikasi baris yang berisi CATALINA_OPTS menjadi seperti ini :
export CATALINA_OPTS="-Dstage=production"
Atau, kita bisa jalankan dengan Jetty melalui Maven
mvn jetty:run -Dstage=testing
Bisa juga melalui environment variabel sistem operasi, di Linux kita set seperti ini.
Konfigurasi Logger
Dengan menggunakan Spring seperti di atas, kita bisa membaca konfigurasi apa saja, misalnya
-
Konfigurasi email : bila aplikasi kita mengirim/menerima email
-
Konfigurasi server lain : bila aplikasi kita berinteraksi dengan aplikasi orang lain, misalnya webservice atau koneksi socket
-
dsb
Walaupun demikian, konfigurasi logger biasanya tidak diload oleh Spring, melainkan langsung dibaca oleh library loggernya.
Kita di ArtiVisi menggunakan SLF4J dan Logback. Cara konfigurasinya mirip dengan Spring. Kita punya satu master file yang akan membaca file lain sesuai isi variabel stage. Untuk itu kita siapkan beberapa file berikut:
-
logback.xml : file konfigurasi utama
-
logback.production.xml : konfigurasi logger production, akan diinclude oleh logback.xml
-
logback.testing.xml : konfigurasi logger testing, akan diinclude oleh logback.xml
-
logback.development.xml : konfigurasi logger development, akan diinclude oleh logback.xml
Berikut isi file logback.xml.
<?xml version="1.0" encoding="UTF-8"?>
<configuration>
<appender name="STDOUT" class="ch.qos.logback.core.ConsoleAppender">
<encoder>
<pattern>%d %-5level %logger{35} - %msg %n</pattern>
</encoder>
</appender>
<appender name="FILE" class="ch.qos.logback.core.FileAppender">
<file>${catalina.home:-.}/logs/kasbon-${stage:-development}.log</file>
<encoder>
<pattern>%d %-5level %logger{35} - %msg %n</pattern>
</encoder>
</appender>
<include resource="logback-${stage:-development}.xml"/>
</configuration>
Seperti kita lihat, file ini berisi konfigurasi yang berlaku umum, seperti appender yang digunakan. Di file ini kita menulis variabel seperti ini
Yang artinya adalah, isi dengan variabel stage, kalau variabel tersebut tidak diset, defaultnya adalah development. Ini sesuai dengan keinginan kita seperti pada waktu mengkonfigurasi Spring di atas.
Isi file logback-development.xml dan teman-temannya dapat dilihat di Github.
Demikianlah tutorial cara mengelola konfigurasi untuk keperluan staged deployment. Semoga bermanfaat.
10 Aug 2011
Di milis manajemen proyek IT sedang rame diskusi tentang CMMI dan Scrum.
Seperti layaknya diskusi yang rame, perdebatan dibumbui dengan segala macam mitos dan ‘FUDification’.
Berikut adalah tanggapan saya tentang mitos yang berkembang mengenai CMMI, dicopy-paste dari posting milis dengan sedikit penyesuaian.
Beberapa mitos yang akan diluruskan :
- CMMI adalah metodologi manajemen proyek yang cenderung waterfall
- CMMI mewajibkan kita bikin banyak dokumen
Pada artikel ini, kita akan meluruskan mitos-mitos tersebut.
CMMI = metodologi, cenderung waterfall
CMMI bukanlah metodologi manajemen proyek seperti
Scrum, IBM Rational Unified Process, XP, apalagi Waterfall.
CMMI sebetulnya sudah pernah saya jelaskan di posting saya sebelumnya. Tapi untuk lebih menyederhanakan lagi, kita bisa analogikan CMMI seperti akreditasi perguruan tinggi. Kalau kita mau daftar kuliah, biasanya kita cari tahu akreditasi kampus yang kita tuju. Semakin tinggi akreditasinya, semakin tinggi ekspektasi kita terhadap kualitas perguruan tinggi tersebut. Akreditasi perguruan tinggi ditentukan oleh banyak hal, diantaranya :
- berapa jumlah dosen yang S3
- berapa karya ilmiah dan penelitian yang dihasilkan dalam satu periode
- dsb
Untuk menentukan suatu kampus mendapat level A, B, atau lainnya, maka ada tim assessor yang akan memeriksa apakah kampus tersebut sudah memenuhi apa yang dipersyaratkan.
Demikian juga dengan CMMI, berisi seperangkat checklist yang bentuknya kira-kira seperti ini:
| Level |
Process Area |
OK |
Not OK |
| 2 |
REQM |
v |
|
| 2 |
PP |
v |
|
| 2 |
PMC |
|
v |
| 2 |
MA |
|
v |
Nah, checklist itu nanti akan dicentang sesuai dengan kapabilitas perusahaan yang diperiksa.
Adapun urusan Scrum, Waterfall, XP, whatever metodologi yang kita gunakan,
hanyalah mencakup sebagian saja dari CMMI.
CMMI itu model untuk menggambarkan organisasi pembuat software yang mature. Apa itu mature? Salah satu karakteristiknya adalah konsistensi. Perusahaan yang gak mature, hasil kerjanya gak konsisten. Project A ontime, Project B molor 3 tahun. Project X bugnya dikit, Project Y isinya bug doang gak ada fiturnya.
Kalau kita bisa mengeksekusi project dengan sukses, kita hanya bisa lulus CMMI level 2. Untuk bisa mendapatkan level 3, kita harus bisa mengeksekusi project dengan sukses secara konsisten.
Untuk bisa konsisten, maka kita harus bisa menduplikasi project sukses ke seluruh perusahaan. Jadi, kalau kita sudah sukses pakai Scrum di project kita sekarang, tetap saja baru level 2. Hanya setelah kesuksesan Scrum bisa direplikasi di keseluruhan perusahaan, barulah bisa level 3.
Seperti juga halnya replikasi resep McDonalds ke seluruh cabang, untuk bisa mereplikasi project sukses ke seluruh perusahaan,
dibutuhkan kegiatan tambahan di level organisasi, misalnya :
- Menulis SOP (OPD)
- Membuat program pelatihan internal (OT)
- Selalu menganalisas prosedur yang sekarang berlaku, supaya bisa diimprove (OPF)
Yang di dalam kurung adalah process area yang bersesuaian di CMMI.
Berurusan dengan perusahaan yang mature akan mengurangi resiko di client. Apa itu resiko?
Buat orang awam seperti kita, resiko adalah simply sekian persen kemungkinan adanya masalah di kemudian hari. Nah, ada perspektif finansial yang kita orang teknis biasanya gak kepikiran. Buat orang finance, persentase tersebut bisa diuangkan. Misalnya kita mau bikin aplikasi costnya 100 M, uangnya minjem ke bank. Karena pada dasarnya bank gak mau rugi, 100 M itu akan diasuransikan sama dia. Jadi kalo projectnya bubaran, kita gak sanggup bayar, hutangnya akan ditalangin sama asuransi.
Asuransi akan lihat, kita pakai vendor siapa. Kalo vendornya gak mature (baca: resiko tinggi) maka premi asuransinya akan tinggi. Akibatnya, biaya pinjaman kita (cost of money) juga tinggi.
Bisa aja kita bayar 100 M (pokok) + 20 M (bunga) + 20 M (asuransi). Padahal kalo vendornya mature, premi asuransinya cuma 5 M. Nah, jadi urusan resiko dan maturity ini bukan semata jargon2 aja, tapi ada duit beneran yang tersangkut di dalamnya.
Demikianlah mitos pertama, CMMI bukan metodologi manajemen proyek, melainkan manajemen keseluruhan perusahaan.
CMMI mewajibkan kita bikin banyak dokumen
CMMI sama sekali tidak mengharuskan kita bikin dokumen apa-apa.
Yang ada, kita harus :
- melakukan project planning (level 2)
- melakukan project monitoring & control (level 2)
- mendefinisikan project life cycle : bisa waterfall, scrum, spiral, cowboy programming juga boleh
Berikut beberapa definisi singkat
- Planning : merencanakan apa yang akan dilakukan
- Monitoring : melihat kondisi aktual, apakah sesuai dengan plan
- Control : melakukan tindakan kalau kondisi aktual tidak sesuai dengan plan
Nah, kita harus membuktikan bahwa kita benar2 melakukan apa yang disuruh. Gimana cara membuktikannya?
Kita bisa :
- Tunjukkan dokumen hardcopy, atau
- Tunjukkan bahwa kita melakukan planning, monitoring, dan control di aplikasi yang kita pakai (Redmine, planningpoker.com, pivotaltracker.com, basecamphq.com, fogbugz, whatever)
Nah, dari 2 cara di atas, kalo kita benar-benar melakukan, akan lebih mudah menunjukkan yang #2. Tapi kalo akal2an, sebenarnya gak planning tapi mau ngakunya planning, akan lebih mudah memalsukan yang #1. Soalnya #2 gak bisa di-back-dated, sedangkan #1 bisa.
Jadi, fokusnya lebih ke melakukan proses, bukan membuat dokumen
Kemudian, ada kesalah-kaprahan juga yang umum terjadi tentang planning. Planning itu tidak sekali saja lalu dipakai sepanjang project. Project plan harus mencerminkan kondisi yang terbaru dari project. Misalnya, kita bikin plan awal (versi 1) selesai 3 bulan. Ternyata waktu monitoring di akhir bulan 1, kita udah tau bahwa gak bakalan selesai dalam 2 bulan sisanya. Kita harus melakukan controlling terhadap projectnya. Tindakan control bisa macam2, bisa kita tambah orang biar tetap selesai dalam 3 bulan, bisa juga revisi plannya sehingga mencerminkan kondisi setelah 1 bulan berjalan.
UUD 45 aja bisa diamandemen, masa project plan gak bisa :D
Contoh lain, mengelola requirement (Requirement Management), Level 2.
S.P 1.1 : Understand Requirement : kita harus memastikan bahwa requirement dipahami.
Gimana cara membuktikannya?
Kalo prosesnya benar-benar dijalankan, kita bisa tunjukkan email dari BA ke Client yang isinya mengkonfirmasi pemahaman BA tentang requirement yang diminta Client.
Atau kalo seperti Scrum, Clientnya hadir di ruangan yang sama, gak nyatet apa2, rekaman audio juga boleh. Intinya, ada sesuatu yang bisa ditunjukkan ke auditor bahwa kita sudah Understanding Requirement.
Kalo prosesnya palsu, artinya sebenarnya gak dilakukan, tapi mau lulus Level 2, maka dibuatlah dokumen palsu. Bentuknya biasanya review report, isinya item2 requirement, lalu nanti ada tandatangan client palsu.
So, overhead dokumen (mis: review report) itu ada kalo kita memalsukan proses.
Selama kita benar-benar menjalankan apa yang disuruh, pasti ada evidence bahwa kita menjalankan, entah itu bentuknya chat YM, email, Skype call, apalah terserah, tidak ada CMMI mewajibkan formatnya harus mp3 atau apa.
SP 1.2 : Obtain Commitment to Requirement : semua pihak harus commit terhadap requirement yang sudah dibuat.
Gimana cara membuktikan bahwa kita comply dengan SP ini?
Paling gampang, BA kirim email ke Client, “Pak, di iterasi ini, kita kerjakan req #12, #14, sama #15 ya. #13 pending dulu aja”
Client reply, “Ok”
That’s it, tunjukkan emailnya ke auditor, beres.
Kalau proses ini tidak dijalankan, akan menimbulkan masalah di kemudian hari. Usernya client bilang A, bosnya user bilang A+, programmer bilang C, PM bilang lain lagi. Sekali lagi, selama prosesnya dilakukan, emailnya pasti ada.
Kalo prosesnya palsu, atau clientnya gaptek gak kenal email, ya dibuatlah dokumen requirement sign off. Orang2 tandatangan. Dokumennya dijadikan evidence.
SP 1.3 : Manage Requirement Changes : kalo requirement berubah, harus di-manage.
Apa itu dimanage?
Dimanage artinya harus jelas :
- apa yang berubah
- siapa yang minta berubah
- siapa yang approve
- apa impactnya ke schedule/cost/effort/cuaca hari ini
Apa buktinya? Email boleh, chat log boleh, rekaman cctv boleh.
Ok, lalu kenapa semua harus ada evidence ??
Berikut joke dari auditor kita dulu,
In God We Trust, everybody else brings data.
Jadi, CMMI = banyak dokumen hanyalah mitos belaka. Untuk bisa melakukan verifikasi, auditor tentu butuh melihat evidence. Di jaman modern seperti sekarang, evidence bentuknya tidak harus dokumen tertulis yang dibuat dengan aplikasi office.
07 Aug 2011
Ada berbagai cara instalasi Redmine, diantaranya:
-
Dijalankan langsung dari command prompt dengan Webrick
-
Dijalankan menggunakan Mongrel dan FastCGI
-
Dijalankan menggunakan Ruby Enterprise Edition dan Passenger
-
Dibuat menjadi war dan dideploy ke application server Java seperti Tomcat, Glassfish, dsb
Pada artikel ini, kita akan mencoba cara terakhir, yaitu menggunakan Tomcat untuk menghosting Redmine.
Ini saya lakukan supaya semua tools manajemen proyek ArtiVisi bisa disatukan di satu Tomcat, sehingga memudahkan kegiatan maintenance.
Sebelum Redmine, Tomcat ArtiVisi juga menghosting :
Dan nantinya, kalau sudah ada waktu dan kesempatan, juga akan menghosting Gerrit
Mari kita mulai.
Instalasi JRuby
Pertama, kita Download JRuby. Setelah itu, extract di folder yang diinginkan (contohnya /opt)
cd /opt
tar xzf ~/Downloads/jruby-bin-1.6.3.tar.gz
chown -R endy.endy /opt/jruby-1.6.3
ln -s jruby-1.6.3 jruby
Daftarkan jruby ke variabel PATH, supaya bisa diakses langsung dari command line.
Tulis baris berikut ini di dalam file ~/.bashrc
export JRUBY_HOME=/opt/jruby
export PATH=$PATH:$JRUBY_HOME/bin
Terakhir, test instalasi JRuby
jruby -v
jruby 1.6.3 (ruby-1.8.7-p330) (2011-07-07 965162f) (Java HotSpot(TM) Client VM 1.6.0_26) [linux-i386-java]
Instalasi Paket Gem
Redmine membutuhkan beberapa library Ruby yang dipaket dalam format gem, yaitu :
-
rack versi 1.1.1 : ini adalah library untuk web server
-
rails versi 2.3.11 (dibutuhkan karena kita akan menginstal Redmine dari Subversion, bukan dari distribusi)
-
jruby-openssl : supaya bisa melayani https
-
activerecord-jdbcmysql-adapter : library untuk koneksi database
-
warbler : packager supaya Redmine bisa dibuat jadi war dan dideploy ke Tomcat
Mari kita install
gem install rack -v=1.1.1
gem install rails -v=2.3.11
gem install jruby-openssl activerecord-jdbcmysql-adapter warbler
Semua paket sudah lengkap, mari kita lanjutkan ke langkah berikut.
Mengambil Redmine dari Subversion Repository
Sebetulnya ada dua pilihan untuk mendapatkan Redmine, download versi rilis atau checkout langsung dari Subversion.
Saya lebih suka checkout langsung supaya nanti lebih gampang upgrade manakala rilis baru sudah terbit.
cd ~/Downloads
svn co http://redmine.rubyforge.org/svn/branches/1.2-stable redmine-1.2
Tunggu sejenak sampai proses checkout selesai. Setelah selesai, kita bisa langsung ke langkah selanjutnya.
Konfigurasi Database
Masuk ke folder Redmine, lalu copy file config/database.yml.example ke database.yml, kemudian edit.
Saya menggunakan konfigurasi development sebagai berikut :
development:
adapter: jdbcmysql
database: redmine
host: localhost
username: redmine
password: redmine
encoding: utf8
Tentunya kita harus sediakan database dengan konfigurasi tersebut di MySQL. Login ke MySQL, kemudian buatlah database dan usernya.
mysql -u root -p
create database redmine character set utf8;
create user 'redmine'@'localhost' identified by 'redmine';
grant all privileges on redmine.* to 'redmine'@'localhost';
Setelah databasenya selesai dibuat, selanjutnya kita akan melakukan inisialisasi.
Inisialisasi Redmine
Pertama, kita inisialisasi dulu session store. Ini digunakan untuk menyimpan cookie dan session variabel.
cd ~/Downloads/redmine-1.2
rake generate_session_store
Setelah itu, inisialisasi skema database.
RAILS_ENV=development rake db:migrate
Isi data awal.
RAILS_ENV=development rake redmine:load_default_data
Setelah terisi, selanjutnya kita bisa test jalankan Redmine.
jruby script/server webrick -e development
Hasilnya bisa kita browse di http://localhost:3000
Kemudian kita bisa login dengan username admin dan password admin.
Konfigurasi Email
Issue tracker yang baik harus bisa mengirim email, supaya dia bisa memberikan notifikasi pada saat ada issue baru ataupun perubahan terhadap issue yang ada.
Redmine versi 1.2 membutuhkan file konfigurasi yang bernama configuration.yml, berada di folder config. Berikut isi file configuration.yml untuk mengirim email ke Gmail.
# = Outgoing email settings
development:
email_delivery:
delivery_method: :smtp
smtp_settings:
tls: true
address: "smtp.gmail.com"
port: 587
authentication: :plain
user_name: "nama.kita@gmail.com"
password: "passwordgmailkita"
Selain itu, kita juga harus menginstal plugin action_mailer_optional_tls, seperti dijelaskan di sini.
jruby script/plugin install
git://github.com/collectiveidea/action_mailer_optional_tls.git
Coba restart Redmine, sesuaikan alamat email kita dengan cara klik link My Account di pojok kanan atas.
Di dalamnya ada informasi tentang email. Ganti dengan alamat email kita.
Kemudian pergi ke menu Administration > Settings > Email Notifications,
kemudian klik link Send a test email di pojok kanan bawah.
Tidak lama kemudian, seharusnya test email dari Redmine sudah masuk di mailbox kita.
Dengan demikian, Redmine sudah berhasil kita instal dan konfigurasi dengan baik.
Selanjutnya, kita akan paketkan supaya bisa dideploy di Tomcat.
Generate WAR
Pertama, kita harus inisialisasi dulu konfigurasi warble.
Dia akan menghasilkan file config/warble.rb. Mari kita edit sehingga menjadi seperti ini.
Warbler::Config.new do |config|
config.dirs = %w(app config lib log vendor tmp extra files lang)
config.gems += ["activerecord-jdbcmysql-adapter", "jruby-openssl", "i18n", "rack"]
config.webxml.rails.env = ENV['RAILS_ENV'] || 'development'
end
Selanjutnya, kita tinggal menjalankan perintah warble untuk menghasilkan file war.
warble
warning: application directory `lang' does not exist or is not a directory; skipping
rm -f redmine-1.2.war
Creating redmine-1.2.war
File war yang dihasilkan tinggal kita deploy ke Tomcat
cp redmine-1.2.war /opt/apache-tomcat-7.0.12/webapps/redmine.war
Jalankan Tomcat, dan Redmine bisa diakses di http://localhost:8080/redmine
07 Jul 2011
Beberapa minggu terakhir ini, saya mencari-cari cara terbaik untuk melakukan development dengan ExtJS.
Tentunya fitur utama yang kita inginkan adalah autocomplete,
sehingga tidak perlu bolak-balik membaca dokumentasi di websitenya.
Setelah berhari-hari mencari, akhirnya saya menemukan Spket IDE.
Di websitenya dinyatakan bahwa Spket sudah mendukung ExtJS versi 4, membuat saya tertarik untuk mencobanya.
Sayangnya, petunjuk instalasi sulit didapat, sehingga harus trial-and-error.
Di artikel ini, kita akan membahas petunjuk instalasi Spket IDE di Eclipse Indigo.
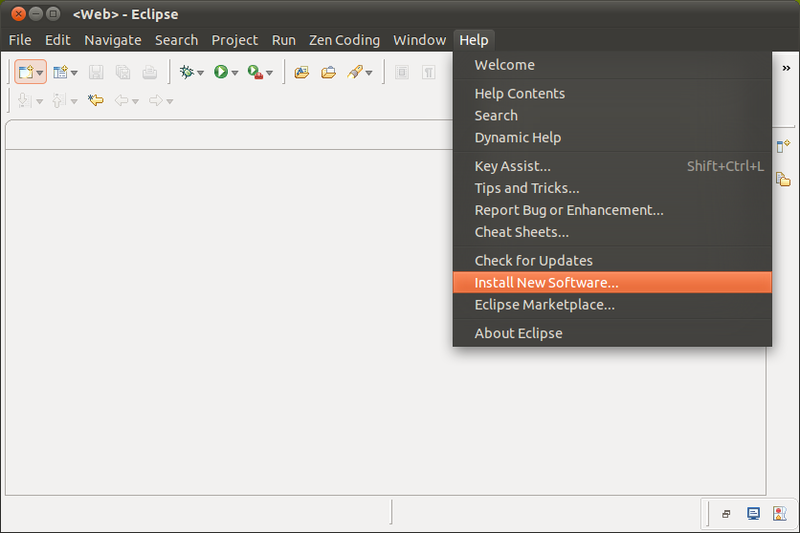
Masukkan Update Site Spket IDE
Tambahkan Update Site yang baru
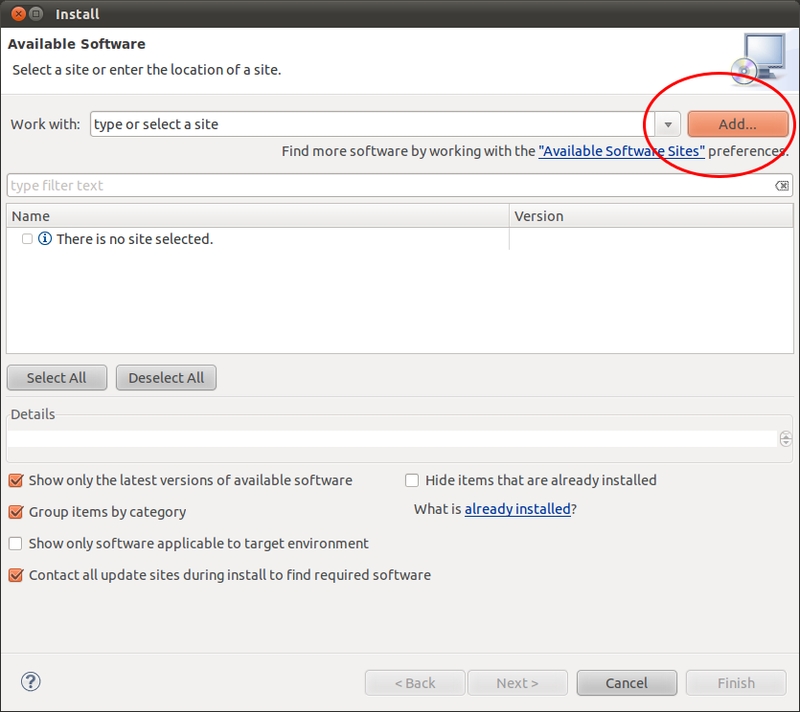
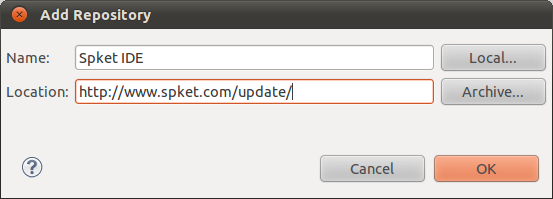
Update sitenya adalah http://www.spket.com/update/
Opsi Instalasi Spket
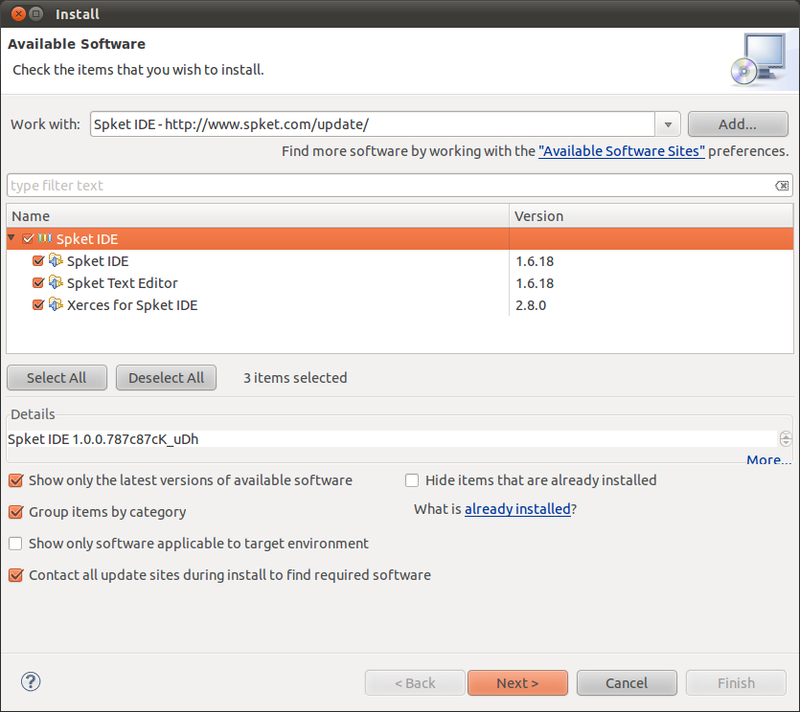
Klik Next
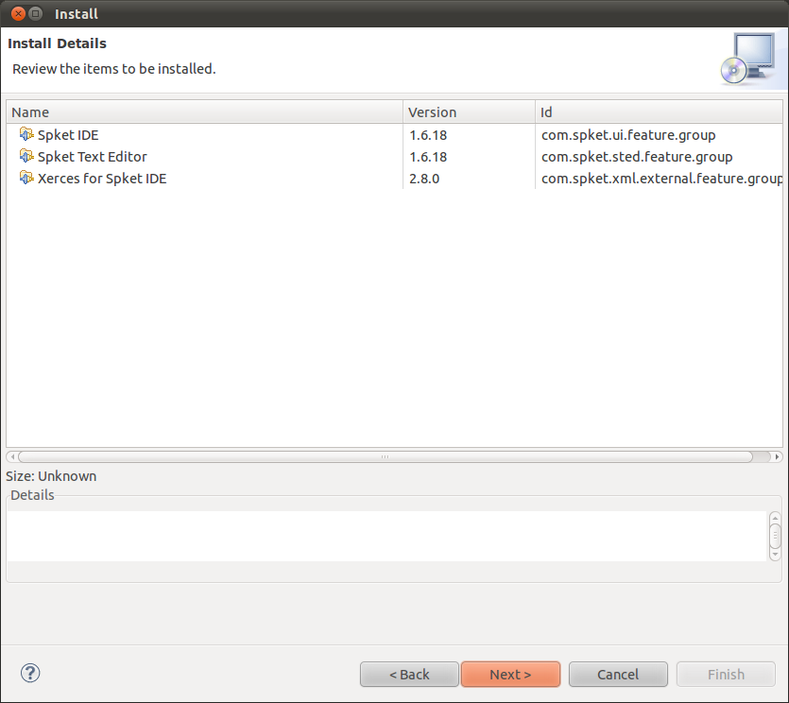
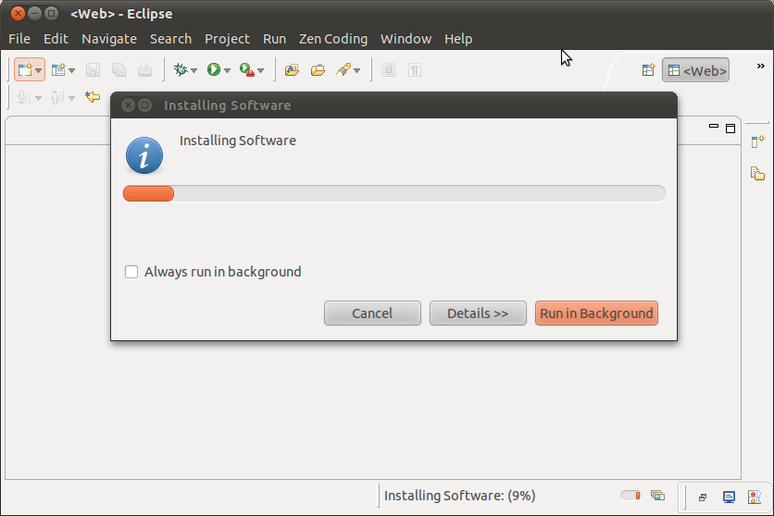

Ada warning, klik saja Yes.
Download Support ExtJS 4
Agar bisa mengenali ExtJS 4, kita harus mengunduh update terbaru dari forumnya.
Entah apa alasannya, tiap ada update baru, versi jarnya tidak dinaikkan dan update sitenya tidak diperbarui.
Ini menyebabkan kita harus mengunduh file dari forum.
Ada dua file yang harus diunduh, yaitu jar
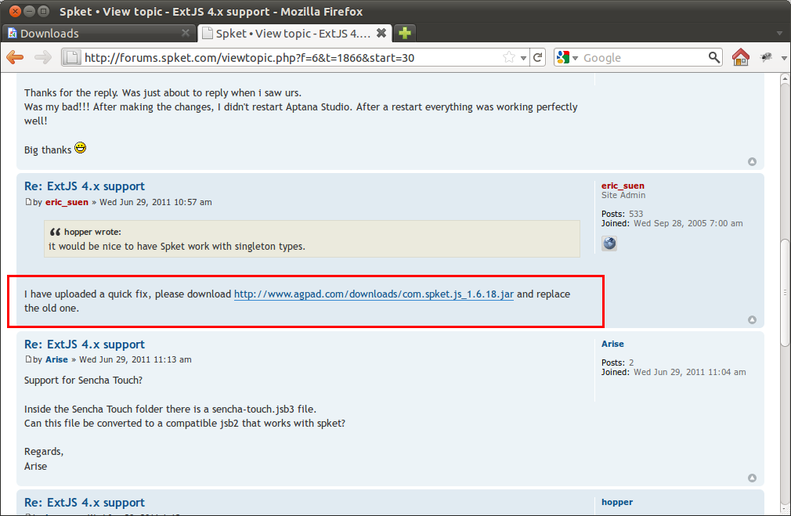
dan jsb
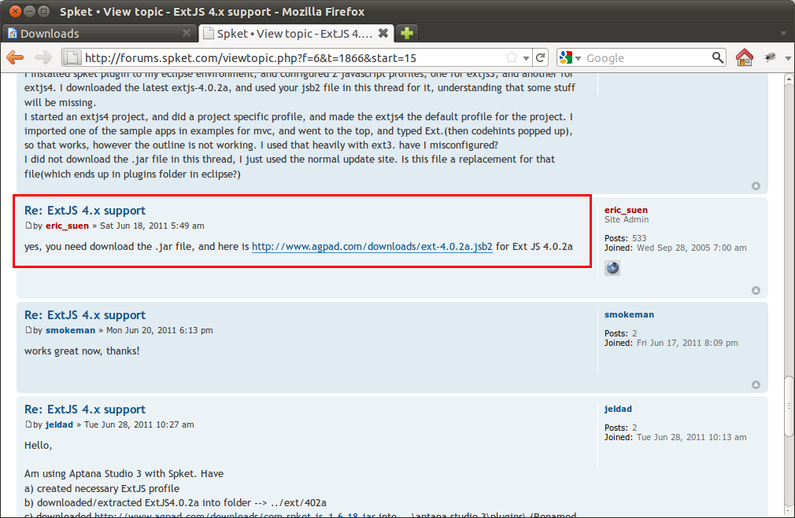 Hasilnya, kita akan memiliki dua file.
Hasilnya, kita akan memiliki dua file.
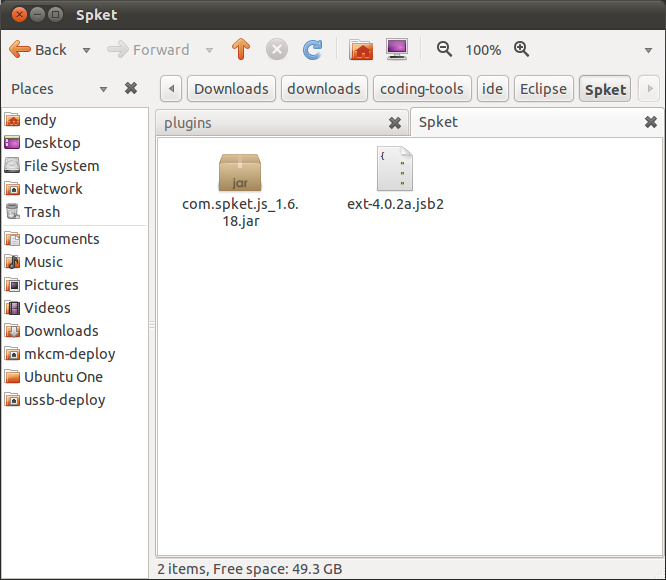
Patch Eclipse
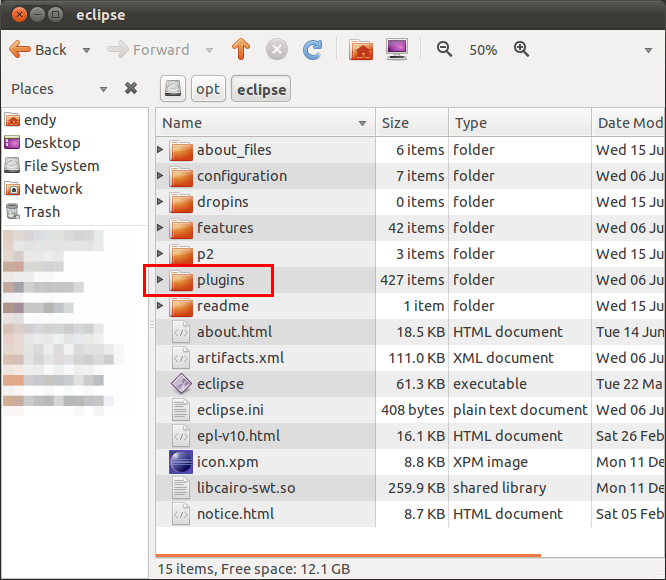
File jar akan kita pasang di folder plugins di tempat Eclipse terinstal.
Ini akan menimpa file dengan nama sama.
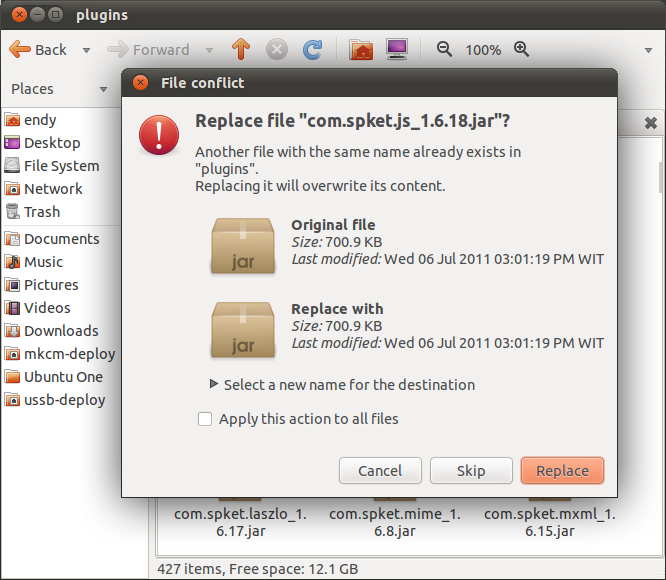
Patch ExtJS
Sedangkan file jsb akan kita pasang di folder ExtJS 4.

Edit jsb
Sayangnya, file jsb ini juga masih ada bugnya. Dia salah menyebutkan nama file dalam folder pkgs.
Kita harus edit, ganti all.js menjadi classes.js.

Konfigurasi Spket
Selanjutnya, kita masuk ke menu preferences untuk melakukan konfigurasi.
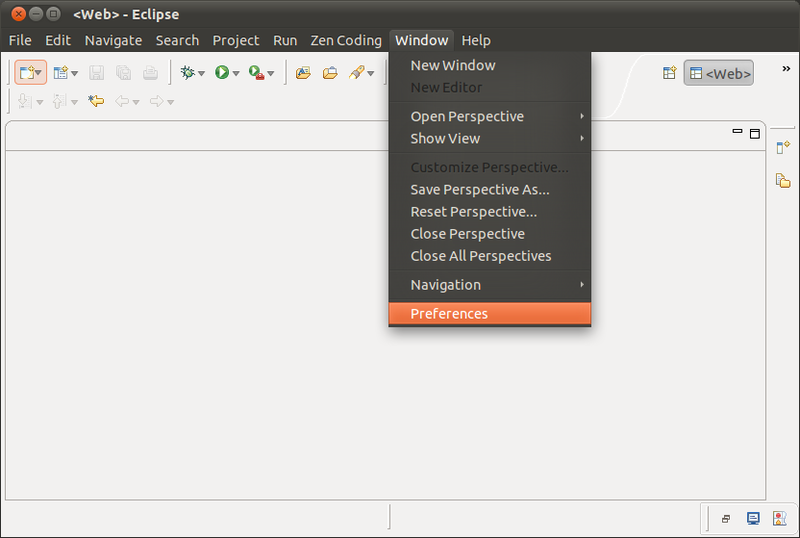 Masuk ke menu Spket - Javascript Profile
Masuk ke menu Spket - Javascript Profile
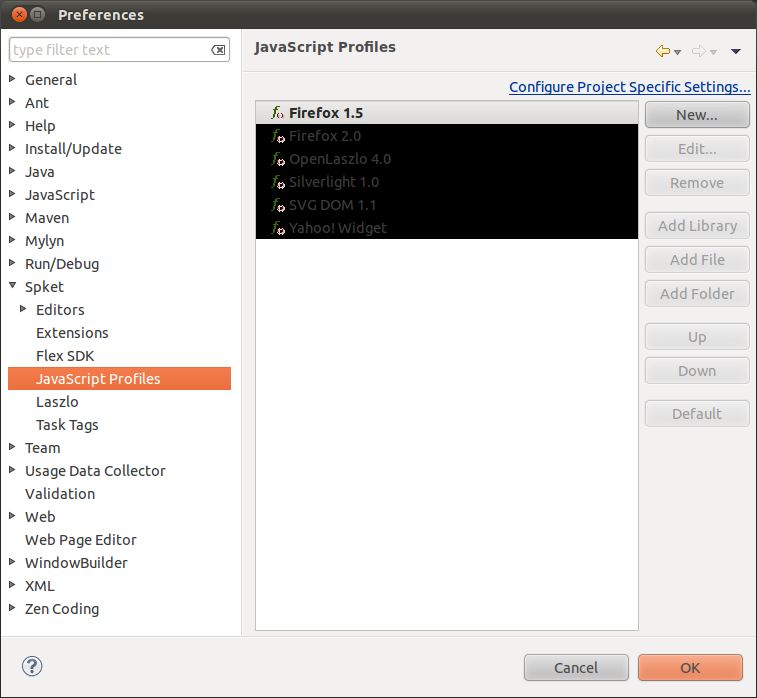 Tambah Profile baru, beri nama ExtJS
Tambah Profile baru, beri nama ExtJS
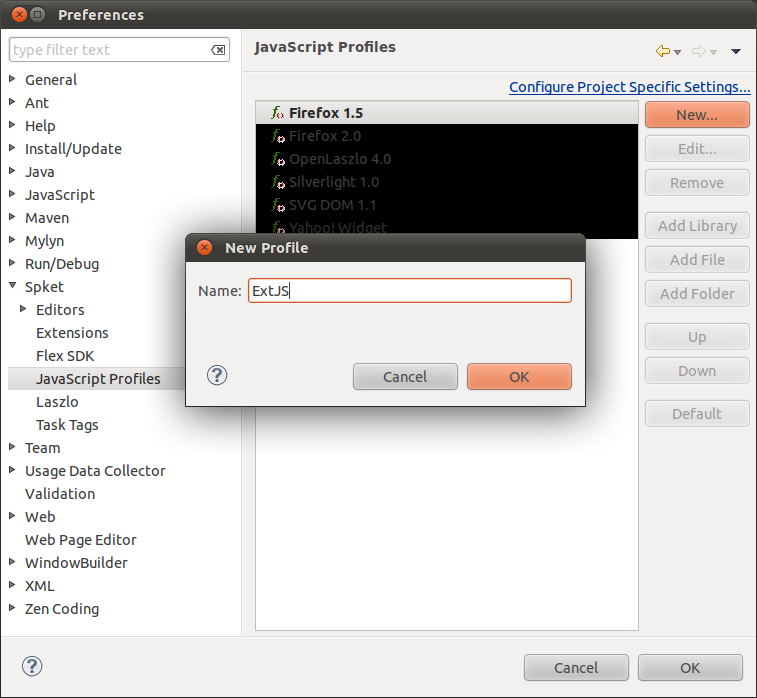 Di profile yang baru saja ditambahkan, Add Library dan pilih ExtJS
Di profile yang baru saja ditambahkan, Add Library dan pilih ExtJS
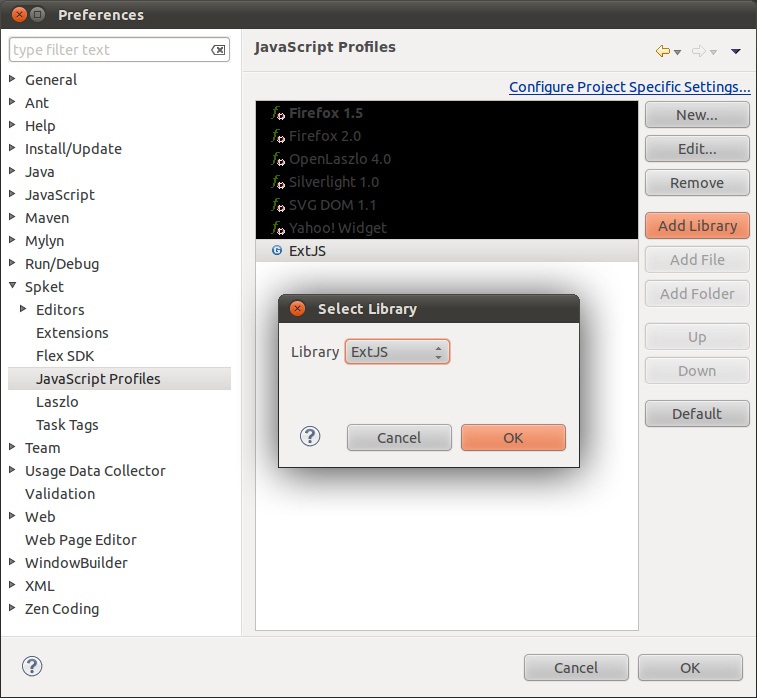 Setelah itu, Add File jsb yang sudah kita edit tadi.
Setelah itu, Add File jsb yang sudah kita edit tadi.
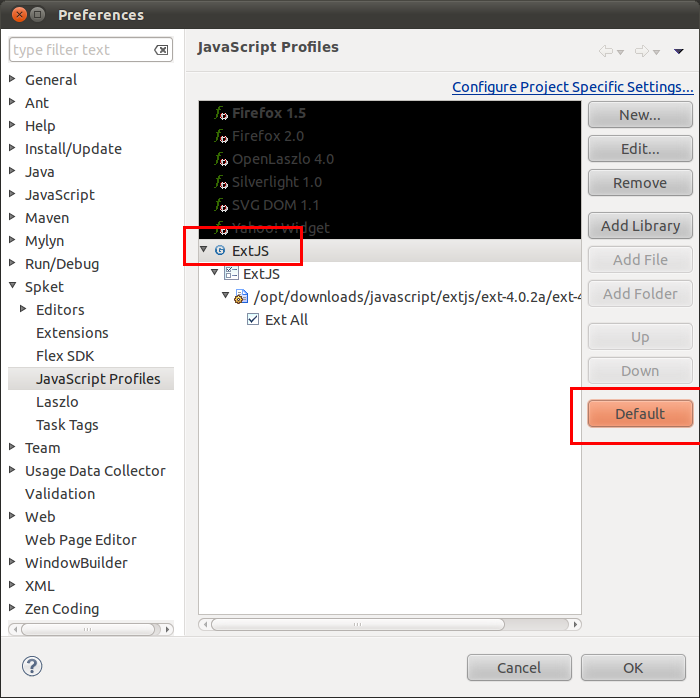
 Lalu, set profile ExtJS menjadi default
Lalu, set profile ExtJS menjadi default
 Kemudian, pergi ke menu General - Editors - File Associations. Pilih file js, dan jadikan Spket sebagai editornya.
Kemudian, pergi ke menu General - Editors - File Associations. Pilih file js, dan jadikan Spket sebagai editornya.
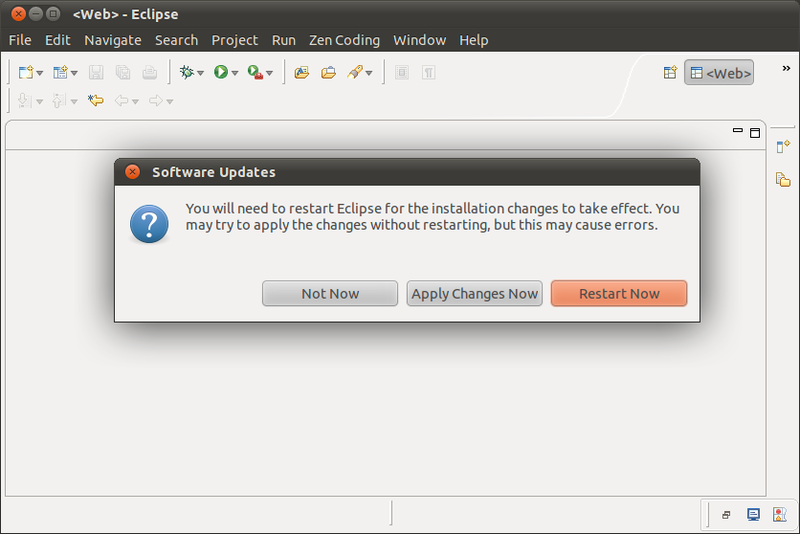
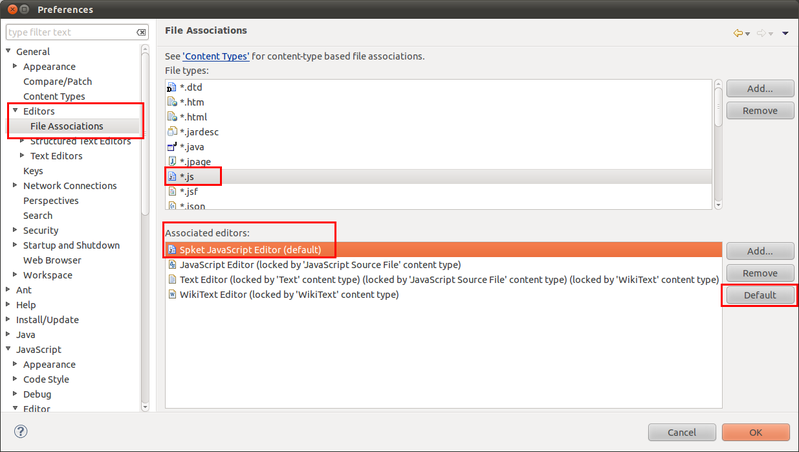 Klik Ok, restart Eclipse.
Klik Ok, restart Eclipse.
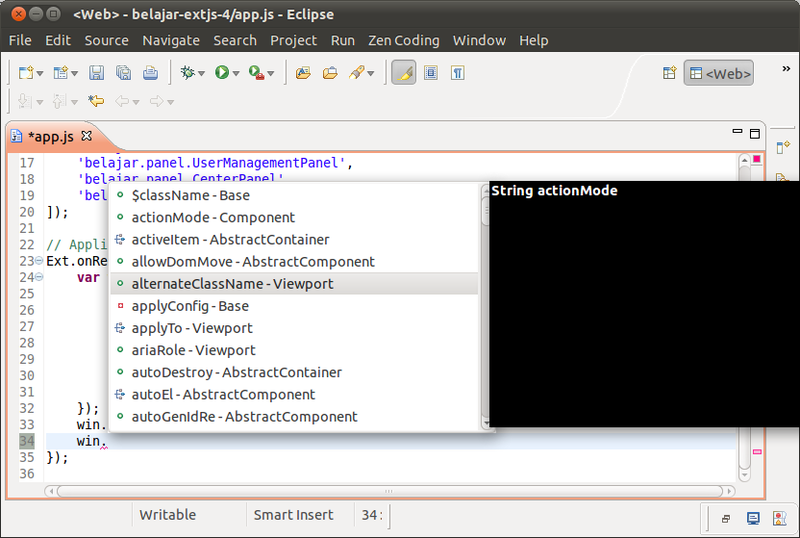
Code Completion
Sekarang kita bisa melakukan code completion pada saat memberi titik di depan object.
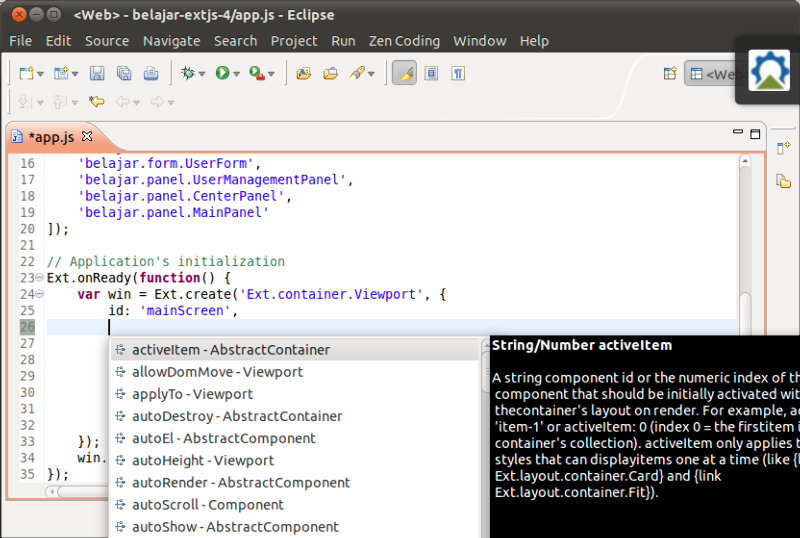
 Atau juga pada saat mengetik di dalam tanda kurung.
Atau juga pada saat mengetik di dalam tanda kurung.
Demikianlah cara instalasi Spket IDE di Eclipse.
