Desain Skema Database
Pada artikel sebelumnya, kita telah belajar bagaimana memulai membuat aplikasi, yaitu dengan cara:
- membuat daftar fitur
- membuat UI Mockup
Kedua langkah di atas membantu kita untuk memvisualisasikan apa yang ada di imajinasi kita menjadi bentuk yang bisa dilihat oleh banyak orang. Ada beberapa keuntungan dari proses visualisasi ini, yaitu:
- mengurangi kepusingan, karena apa yang sebelumnya cuma dibayangkan, sekarang terlihat bentuknya
- menunjukkan kekurangan dalam imajinasi kita. Seringkali saya mendapati ada informasi yang kurang sehingga harus ditanyakan lagi ke user. Kali lain, saya mendapati ternyata perpindahan antar screen tidak sistematis sehingga membingungkan user. Atau saya terlalu kompleks mendesain tampilan yang seharusnya bisa lebih sederhana.
- menjadi bahan diskusi dengan user, menghindarkan kita dari membuat sesuatu yang tidak dibutuhkan user.
- sebagai pedoman kita untuk merancang skema database
Poin terakhir tersebut akan menjadi bahasan kita pada artikel kali ini.
Saya tidak akan membahas tentang teori normal form. Seharusnya para mahasiswa informatika sudah mempelajarinya di mata kuliah Basis Data yang biasanya diberikan di semester 3. Silahkan ambil lagi mata kuliah tersebut di tahun/semester depan kalau ternyata Anda ketiduran waktu dosennya menerangkan. Sedangkan pembaca yang tidak kuliah di informatika (seperti saya), bisa baca-baca referensi dari Wikipedia atau tutorial di sini.
Artikel ini ditulis dengan asumsi pembaca sudah paham apa itu normal form. Silahkan belajar dulu kalau belum paham, baru kembali lagi ke sini.
Sebelum kita mulai mendesain skema database, ada satu hal penting yang kita perlu camkan baik-baik
Hasil desain, baik itu skema database, class diagram, flowchart, dan lainnya, bukanlah merupakan hasil sekali pukul. Dia adalah suatu produk yang harus terus disempurnakan bahkan sampai setelah aplikasinya go live.
Dengan demikian, adalah lumrah kalau kita merevisi skema database berkali-kali. Setelah go-live saja bisa berubah, apalagi pada saat development.
Desain tabel master
Dalam mendesain skema database, kita mulai dulu dengan yang paling sederhana, yaitu tabel master. Tabel master biasanya tidak berelasi ke tabel lain. Kalaupun ada relasi, biasanya relasi dengan tabel master lainnya. Contohnya, master pegawai berelasi ke master kabupaten, kecamatan, kodepos, tingkat pendidikan, dan lainnya. Karena dia sederhana, maka dalam membuat aplikasi, biasanya tabel-tabel master ini didefinisikan duluan.
Ada pola yang biasa saya gunakan dalam mendesain tabel database (baik master data maupun transaksi), yaitu:
- harus ada primary key yang berupa surrogate key
- karena pakai surrogate key, maka kandidat natural key menjadi kolom biasa yang diberikan unique constraint
- buat kolom lain sesuai yang ada di UI mockup
- untuk menyimpan nilai uang, gunakan DECIMAL, bukan FLOAT atau DOUBLE, supaya kita bisa mengontrol pembulatan dan tingkat presisi
Whoa, apa itu surrogate key dan natural key?
Mari kita bahas.
Menentukan Primary Key
Misalnya kita akan menyimpan data pegawai dalam tabel m_pegawai. Informasi pegawai memiliki beberapa data sebagai berikut:
- nip (nomor induk pegawai), dijamin unik karena tiap pegawai pasti beda.
- nama, tidak unik. Agus, Budi, Cahyo biasanya banyak yang pakai.
- email, juga unik. Tidak mungkin satu email dipake rame-rame.
Dari ketiga data di atas, hanya dua yang bisa jadi primary key yaitu nip dan email, karena secara proses bisnis, nilainya harus unik di tiap record pegawai. Kedua data ini, bila kita pilih salah satunya menjadi primary key, maka disebut dengan istilah natural key, artinya primary key yang diambil dari data yang memang sudah ada.
Selain natural key, kita juga bisa membuat data lain yang tidak berkaitan dengan proses bisnis. Misalnya menambahkan primary key berupa kolom id di tabel pegawai yang nilainya kita konfigurasi supaya bertambah satu (increment) tiap ada record baru yang dimasukkan ke tabel. Kolom id ini disebut dengan istilah surrogate key.
Natural vs Surrogate
Keuntungan kita menggunakan natural key adalah, datanya sudah ada. Dengan demikian kita tidak perlu menambah kapasitas penyimpanan untuk satu kolom khusus primary key.
Kerugian dari natural key adalah nilainya bisa berubah. Sebagai contoh, bila perusahaan merger, maka nilai nip bisa dipastikan akan menyesuaikan dengan perusahaan lain yang dimerger. Bisa formatnya ikut perusahaan lain tersebut, dan bisa juga membuat format baru sesuai kesepakatan bersama.
Kalau gitu, email saja yang jadi primary key.
Email justru lebih sering berubah. Gak perlu merger, cukup ada layanan yang menawarkan kapasitas lebih besar, orang langsung bikin akun email baru.
Lalu memangnya kenapa kalau berubah?
Yang namanya primary key, akan digunakan di tabel lain sebagai foreign key. Apalagi untuk tabel master, pasti dia akan direlasikan di berbagai tabel lainnya. Jika primary key berubah, maka semua tabel lain harus ikut diupdate isi foreign key-nya. Ini akan membutuhkan locking yang luas karena harus meliputi banyak tabel sekaligus. Semakin luas locking, semakin lemot performance, karena proses lain harus antri mendapatkan lock.
Masalah kedua, penggunaan natural key cenderung akan mengarah pada penggunaan compound/composite key, yaitu primary key yang terdiri dari dua atau lebih kolom. Ini akan lebih merepotkan lagi, karena foreign key dari composite key juga akan terdiri dari dua/lebih kolom.
Kekurangan dari surrogate key adalah ada tambahan space harddisk untuk menyimpan data kolom tambahan. Juga tambahan space untuk membuat index dari natural key (yang seharusnya otomatis terindex bila dia menjadi primary key).
Lalu, sebaiknya pakai natural key atau surrogate key?
Saya selalu pakai surrogate key. Sebabnya karena space harddisk semakin lama semakin murah, sedangkan locking problem dan composite key akan memakan mandays programmer yang semakin lama semakin mahal.
Strategi Key Generator
Karena nilai dari surrogate key tidak berhubungan dengan data yang diwakilinya, maka kita bisa melakukan optimasi dalam pemilihan algoritma untuk menghasilkan nilai baru. Ada beberapa strategi yang biasa digunakan:
- Auto increment / sequence. Cara ini disebut dengan berbagai istilah, misalnya AUTO_INCREMENT (MySQL), SEQUENCE (Oracle), SERIAL (PostgreSQL), IDENTITY (MS SQL Server), AutoNumber (MS Access), dan lainnnya. Intinya adalah penggunaan tipe data integer yang nilainya bertambah terus.
- UUID / GUID. Tipe datanya 32 karakter alfanumerik, bisa diwakili di database dengan CHAR atau VARCHAR.
Pilih yang mana?
Saya biasa pakai UUID, karena dia dijamin unik siapapun yang menjalankan generator. Ini akan sangat berguna dalam skenario database terdistribusi seperti ini.
Misalnya database kita split menjadi database kantor pusat dan kantor cabang. Masing-masing cabang insert data transaksi ke database yang ada di kantor cabang. Pada sore hari, database cabang diupload ke kantor pusat dan digabungkan ke database pusat, bersama-sama dengan data transaksi dari cabang lain.
Bila kita menggunakan sequence, akan terjadi duplikasi primary key, karena masing-masing cabang memulai sequence dari angka 1. Cabang A akan punya data 1 - 100, demikian juga cabang-cabang lain.
Lain halnya bila kita menggunakan UUID. Nilai yang dihasilkan oleh cabang A dijamin berbeda dengan nilai yang dihasilkan cabang B. Dengan demikian, kita tinggal insert data cabang A dan cabang B ke database pusat tanpa ada primary key yang bentrokan.
Tabel Transaksi
Sekarang kita beranjak ke tabel untuk menyimpan data transaksi.
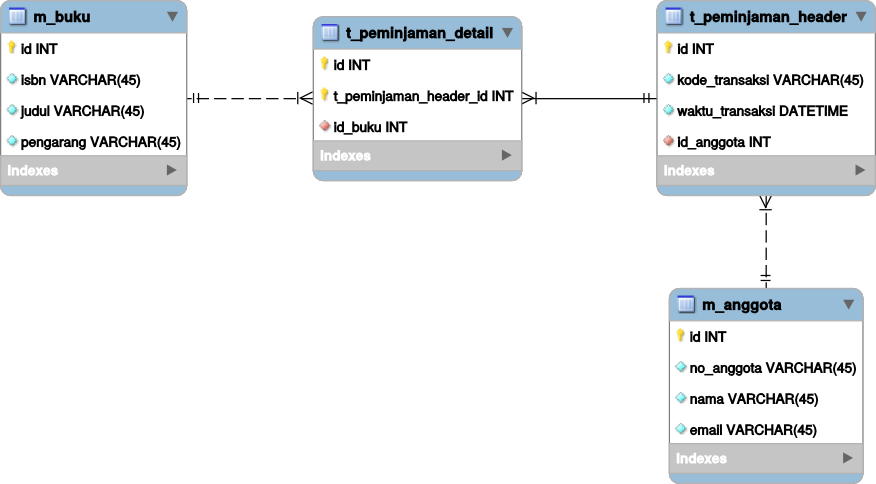
Pola yang umum dipakai adalah relasi master-detail-header seperti ini

Pola ini bisa kita gunakan untuk aplikasi perpustakaan seperti ini
Ataupun untuk aplikasi bengkel, dimana detailnya ada dua (part dan jasa)
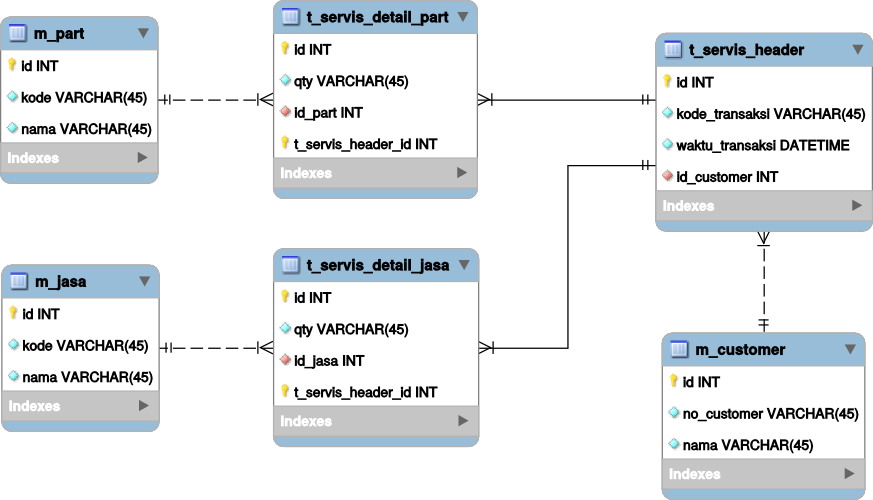
Pola yang sama bisa digunakan dalam pencatatan transaksi lain, misalnya:
- jurnal akuntansi : jurnal_header berisi tanggal dan keterangan, jurnal_detail berisi id_akun, debet/kredit, dan nilai nominal
- transaksi di minimarket : transaksi_header berisi tanggal dan nama kasir, transaksi_detail berisi id_produk, qty, harga_satuan
- keluar/masuk barang di gudang : transaksi_header berisi tanggal, transaksi_detail berisi id_barang, qty
- dan sebagainya
Identifying Relationship
Pembaca yang teliti akan melihat bahwa garis penghubung relasi antara header dan detail berbeda dengan detail dan master. Header-detail garisnya menyambung sedangkan detail-master putus-putus. Garis tersambung disebut dengan istilah identifying relationship, yaitu hubungan parent-child. Artinya, kalau induknya (record di tabel header) dihapus, maka anaknya (record di tabel detail) juga harus dihapus karena sudah tidak relevan lagi.
Berbeda dengan master-detail. Kalau masternya dihapus, belum tentu data transaksinya juga ikut dihapus. Bisa jadi relasinya cuma diset menjadi NULL saja, tapi datanya tetap ada dan tetap bisa dihitung.
Tabel Akumulasi
Terakhir, kita bahas tentang tabel akumulasi. Tabel ini sebetulnya tidak wajib dibuat. Kita membuat tabel ini terutama untuk alasan performance.
Misalnya kita ingin menampilkan data jumlah stok buku di satu hari tertentu. Atau kita ingin mencari berapa jumlah barang yang tersisa untuk satu jenis barang tertentu.
Tanpa tabel akumulasi, kita harus mencari dulu saldo awalnya, kemudian kita melakukan penjumlahan berapa penambahan dan pengurangan selama periode bisnis berjalan. Kalau bisnisnya baru jalan 3 hari tidak masalah, tapi bagaimana kalau sudah jalan 3 tahun? Tentu ada jutaan record yang harus dijumlahkan oleh database dalam sekali request. Bagaimana kalau usernya banyak?
Untuk mengatasinya, kita buat tabel untuk akumulasi. Berikut skemanya
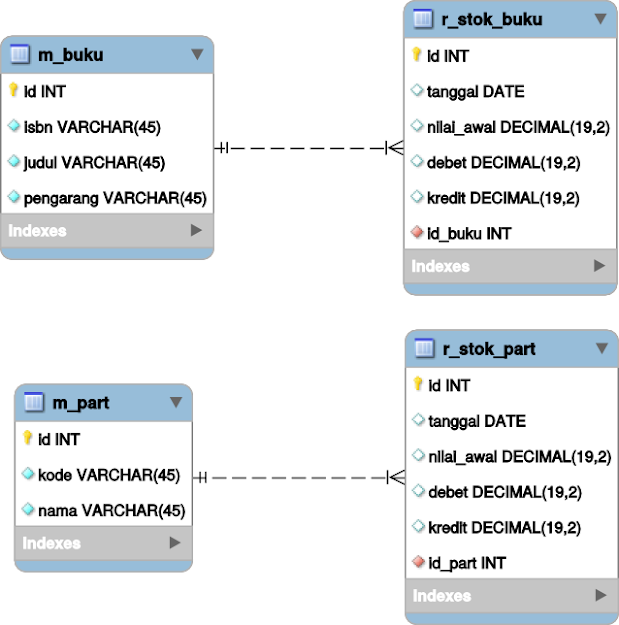
Penjelasan kolomnya sebagai berikut:
- id : surrogate key
- id_xx : relasi ke tabel master barang/akun/produk/dsb
- tanggal : supaya memudahkan, kita buat satu record per hari
- saldo_awal : nilai di awal hari
- debet : penambahan nilai dalam hari itu
- kredit : pengurangan nilai dalam hari itu
Kok gak ada saldo akhir?
Ya kan tinggal dihitung saja. Saldo akhir = saldo awal + debet - kredit. Gampang kan?
Ada dua pilihan metode dalam mengisi tabel akumulasi ini:
- Diupdate setiap insert transaksi. Jika menggunakan metode ini, jangan lupa menggunakan database transaction untuk menjaga konsistensi data.
- Diupdate secara batch di akhir hari. Jika menggunakan metode ini, jangan lupa memasang lock supaya tidak ada orang yang insert record baru pada saat kita sedang menghitung akumulasi. Biasanya kalau trafiknya tinggi dan harus selalu online (seperti ATM bank), perlu menggunakan teknik shadow balance supaya transaksi bisa terus jalan walaupun batch update sedang berjalan.
Kesimpulan
Poin penting yang bisa diambil dari artikel ini:
- natural key vs surrogate key
- pola master-detail-header
- pola master-akumulasi
Skema database dibuat menggunakan aplikasi MySQL Workbench. Desain skema pada contoh di atas bisa diunduh di sini
Demikianlah pola desain skema database yang biasa saya gunakan untuk membuat aplikasi bisnis. Pada posting selanjutnya, kita akan bahas apa saja class dan package yang harus kita buat pada waktu coding. Stay tuned.